论文简介
- 地址:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 。
- 论文主要结合了
pointwise group convolution和channel shuffle,大大减少了计算量,同时仍然能够保证准确度。 - 在ImageNet分类任务和COO物体检测任务中表现得都很好,模型有很好的泛化能力。比mobilenet在分类任务上的top-1 error降低了7.8%。
- shufflenet在基于ARM的移动设备上比AlexNet速度要快13倍,准确度仍然能够媲美。
introduction
- 当前的小网络,比如说
Xception或者ResNeXt等,由于1X1的的卷积操作,在速度上反而变得低效,因此本文pointwise group convolution的操作,减小1X1XN卷积操作的计算量,为了避免group convolution的缺点(特征之间没有流通),论文采用了一种新型的channel shuffle的操作。来实现特征channel之间的信息流通。 - 在网络参数相同的情况下,shufflenet可以比其他网络有更多的feature channel,性能也更好。
- 最开始的GConv(group convolution)是group之间没有信息流通,相互独立的,之后出现了一种
random shuffle的操作,但是这个之后很少被研究。论文中提出了一种fully related的GConv,每个输出channel都与所有group中的feature channel相连接,即channel shuffle。具体形式可以见Fig.1。
methods
Channel Shuffle for Group Convolutions
传统的GConv没有group之间的信息流通,而论文中的GConv实现了信息流通。
假设一个卷积层被分为$g$ groups,输出有$g\cdot n$ channels,论文中首先将该层输出reshape成$(g,n)$,经过transpose和flatten之后输出到下一层。在这里需要注意:即使2个feature layer的group数量不同,论文中的group convolution仍然有效,同时channel shuffle是可微的,因此支持端到端的训练。
ShuffleNet Unit
- 论文对于小网络,提出了
ShuffleNet Unit,针对residual blocks,论文在branch中添加了GConv和channel shuffle的过程,减少计算量。具体可以见下图
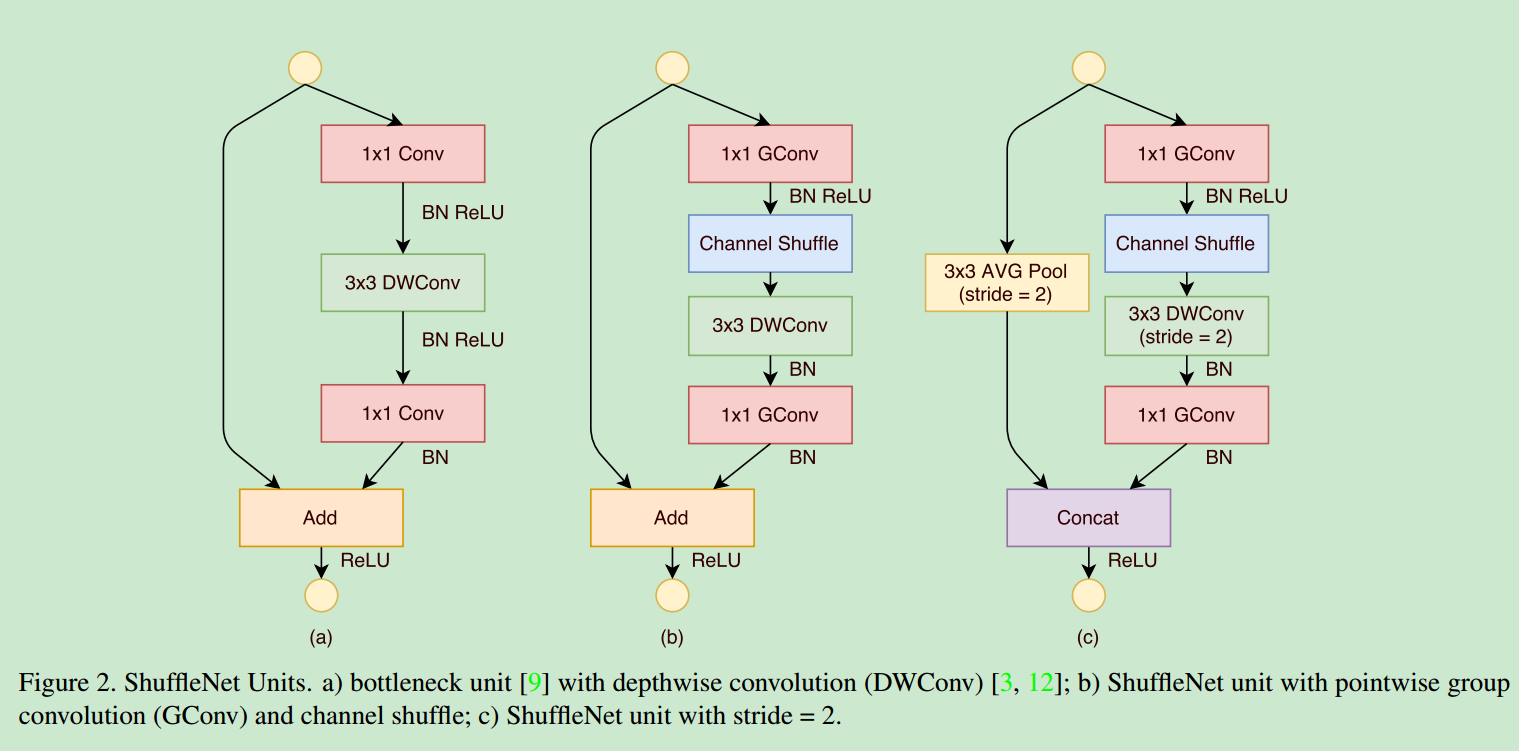
- 经过实验证明,虽然depthwise convolution操作的参数很少,但是其在低功耗设备上的性能却很差,因此shufflenet中,只在bottleneck中使用
depthwise convolution,防止计算过载。
Network Architecture
- 主要是
input->conv->max pool->shuffle unitX3->global pool->FC,网络具体设计参数如下图
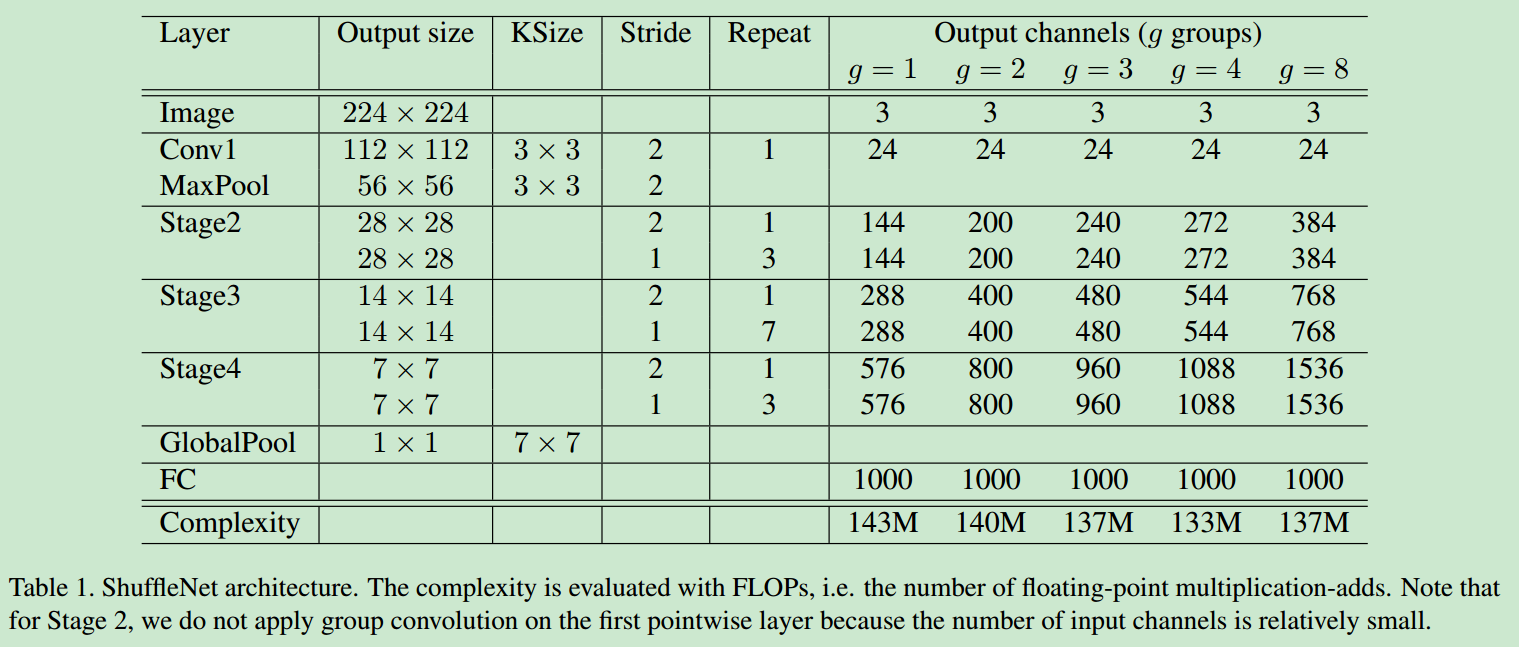
- group number越大,输出channel就越多,即可以表达出更多的特征。
experiment
- 训练过程中,只使用很少的数据增强,因为对于这种小网络,更容易发生欠拟合(数据增强在模型过拟合时比较有用)。
- 作者使用不同的channel规模以及不同的group number进行训练,在相同channel规模的情况下,没有channel shuffle时,模型误差随group number增加会增加,而在有channel shuffle时,模型误差随group number增加有略微减小。channel规模越大,误差越小(有更多的feature得以表达)。
- 作者对比了shufflenet与VGG-16、GoogleNet、SqueezeNet等,在保证网络参数量很小的情况下,模型误差仍然比他们更小。
- 为了验证shufflenet的泛化能力,本文借鉴Faster-RCNN的框架,在COCO数据集上使用shufflenet进行了物体检测的测试,比mobilenet的性能要好。
- 在ARM平台上进行了测试,在保证准确度的情况下,shufflenet比一些AlexNet-Level的模型要快13倍左右。