论文简介
- 地址:Xception: Deep Learning with Depthwise Separable Convolutions。
- 作者受到inception的启发,提出了xception结构,inception中的inception模块用
depthwise separable convolution(DSConv)替代,这个在imageNet上比inception V3的效果要好。 - 由于xception与
inception V3的参数相同,因此模型性能的提升不是因为参数量,而是因为模型结构的改进。
introuction
- inception网络借鉴了
network in network的思想,与之前的VGG-style的网络结构是不同的。它在与卷积结构类似的情况下,能够学习到更丰富的信息。 - inception模块是将输入先通过1X1的卷积,然后将channel分为几组,每组单独经过3X3或者5X5的卷积,处理之后,再进行concat,得到输出。
- 关于几种inception模块的结构,可以见论文,这里不详细给出。
The Inception hypothesis
- 该假设即:feature channel之间充分解耦,因此最好不将所有通道都连接在一起,而是分成几块,单独处理,也就是上面所说的inception模块的处理过程。
DSConv
- 在TF等库中,DSConv都是先进行channel-wise convolution,再进行1X1的convolution;而inception中是先进行1X1的convolution。
- 在inception中,1X1convolution等卷积操作后都会加上RELU非线性化,而DSConv中则没有这个RELU的激活操作。
Xception architecture
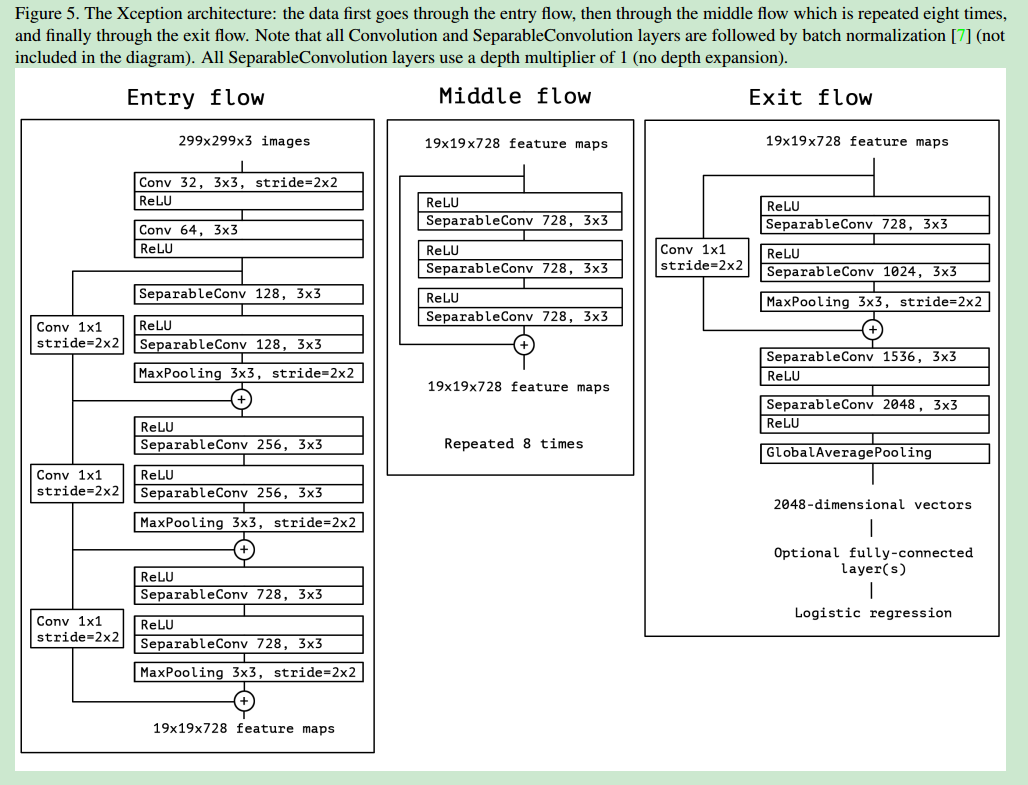
- xception是完全基于SDConv layer的,同时使用了residual connection的结构,整体网络的结构如下:
experiment
dataset
- 作者在ImageNet和JFT数据集上,对xception和inception V3做了对比实验测试(两者参数量类似,注意:在inception V3中,没有引入residual的结构)
regularization
- 使用L2正则化进行正则化。
- 在imagenet中使用了dropout,在JFT中没有使用,因为他的数据量很大,不会造成过拟合。
- 在inception V3中可以选择
Auxiliary loss tower的结构,使得网络的分类错误可以更早地进行backpropagate,这也有利于网络的正则化,本文测试时没有添加这个结构。
result
- 在imagenet分类中,xception的
top-1 accuracy和top-5 accuracy比VGG16、ResNet-152、inception V3都要高。 - 在JFT中,带有FC layer的xception的MAP性能最好(在这里与inception V3进行了比较)。
- 带有residual结构的xception比没有的性能要好。
- 在1X1的pointwise convolution操作后,不加激活函数(相当于线性直连)比加上RELU或者ELU的操作都要好。
conclusion
- 主要就是提出了xception这种模型,将DSConv和residual结构相结合,证实了DSConv的作用,同时也通过实验,验证了诸如1X1 convolution操作之后是否要加激活函数以及residual模块的作用等。