论文简介
- 地址:Fully Convolutional Instance-aware Semantic Segmentation。
- 论文是首次使用
end to end的方法实现实例分割,它同时完成对物体实例的检测与分割,在精度和速度都达到了state of art的水平。同时赢得了coco2016的分割比赛。
introduction
- FCN被广泛应用于语义分割,但是它具有平移不变性,即相同物体在不同位置仍然被识别为同一个类别,而这不符合实例分割的要求。因此需要设计一些translation-variant的方法来解决传统CNN中存在的问题。
- 主流的实例分割方法主要是将该任务分为三个步骤
- FCN用于提取特征,得到共享的feature maps
- 使用pooling layer,将每个ROI中对应的
shared feature maps转化为固定大小的ROI feature maps,作为后续步骤中网络的输入(网络输入需要是固定大小的) - 使用FC layer,将
ROI feature maps转化为ROI mask。这一步中,为模型引入了平移变化的特性。
- 上面的方法有几个缺点
- 在feature map做warp和resize的时候,会丢失部分空间信息(因为需要将feature map转换为固定大小),这会降低分割的精度。
- 第三个步骤中的FC layer的参数量太多(之前很多网络中的FC layer都占据了整个网络绝大部分的参数量)
- 在第三个步骤上,ROI的计算没有共享计算。
- 最近有学者提出了基于instance mask proposal的FCN,但是这种网络无法检测物体的类别,需要再使用检测算法去对物体进行detection。
本文的模型
简介
- FCIS是第一个
end to end的实例分割网络。网络中的feature maps和score map都被之后的物体分割和检测任务所共享。同时在per-ROI的计算中,也不涉及到warp和resize。 - FCIS是基于region proposal的,不是基于滑动窗口的。
Position-sensitive Score Map Parameterization
- FCN可以得到每个pixel属于某个class的confidence,在不同的位置都会预测出相同的结果,因此仅仅用这种
score map来对pixel进行表示的话,无法区分不同的instance。 - 针对上述问题,论文5(
Instance-sensitive fully convolutional networks)中提出了一种具有translation-variant性质的FCN。使用$k^2$个score map给出被均匀划分为$k \cdot k$个cell的object的score map,每个score map的大小相等。每个score map都代表pixel在特定位置属于某个instance的概率。 - 对于特定大小的滑动窗口,通过计算对应score map中$k \cdot k$的cell可以计算其
pixel-wise foreground likelihood map。 - 上面论文中的方法有几个缺点:
- 用于检测的滑动窗口的大小的固定的。
- 该网络需要对不同尺寸的图像进行处理,得到不同尺寸的instance。
- 这种方法无法识别出物体类别。
Joint Mask Prediction and Classification
- 之前的CNN实例分割方法基本上都是单独运行分割和检测两个任务(这两个任务是独立的,先进行分割,再做检测)。作者推断这种方法没有完全利用网络中的数据信息。
- FCIS改进了
position-sensitive score map,使得segmentation和detection两个任务可以同时进行,它们都共享CNN出来的score map,这种方法也减少了网络参数,同时避免了网络的设计选择问题。 - 具体的对比以及框图如下。
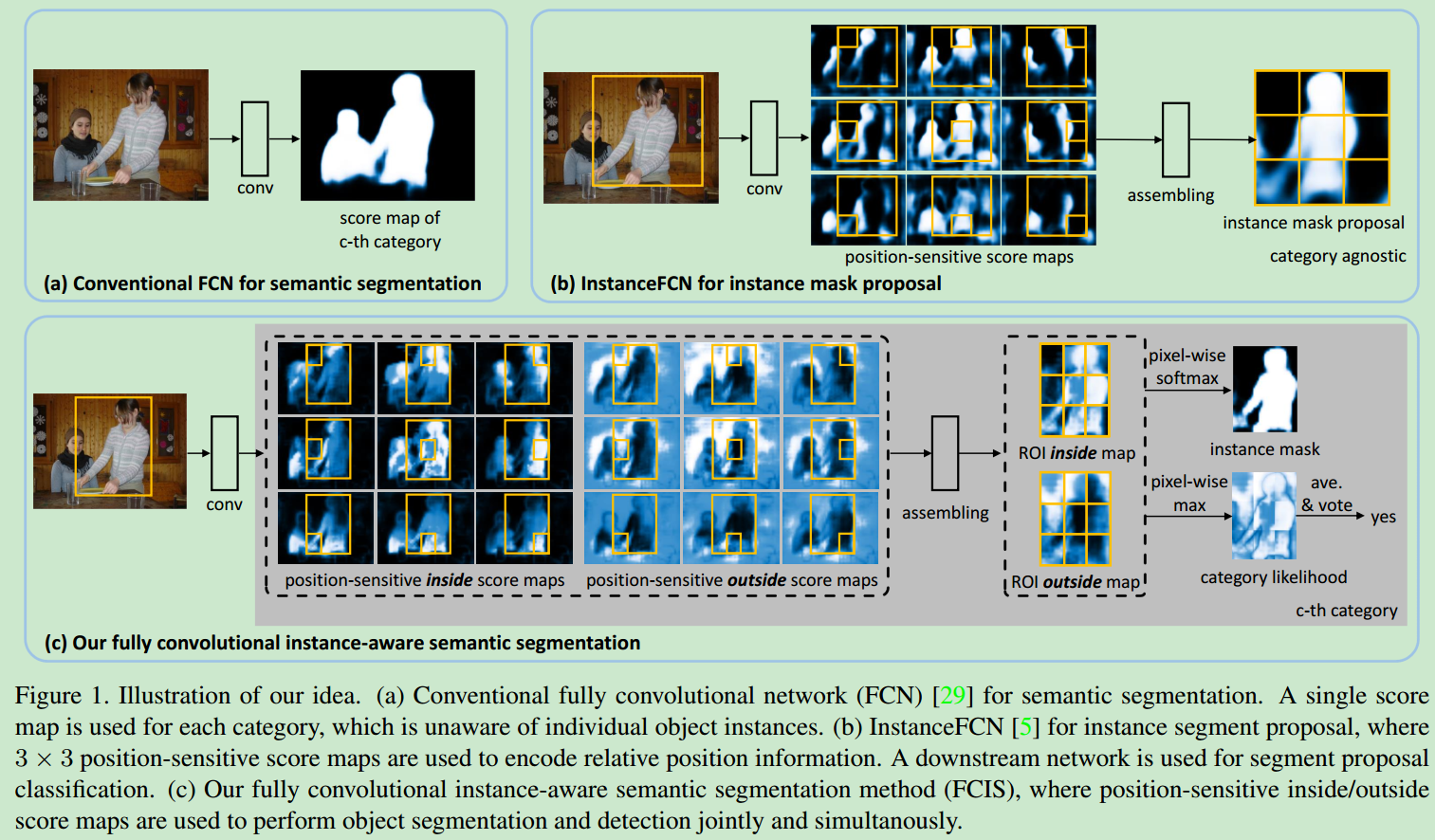
- 在FCIS中,score map有inside和outside两种,分别用于segmentation和detection,他们经过1X1的convolution layer就可以得到每个pixel的结果。对于下面三种可能的结果。
- (1)high inside score and low outside score: detection+, segmentation+
- (2)low inside score and high outside score: detection+, segmentation-
- (3)both scores are low: detection-, segmentation-
对于每个pixel,使用max operation可以区分(1,2)和(3),使用softmax operation可以区分(1)和(2)。使用全局池化,可以得到该ROI的detection结果;使用softmax,也可以给出每个pixel的类别,最终得到ROI的mask。
An End-to-End Solution
- 作者采用了ResNet的结果,舍弃了最后的1000FC layer,之前ResNet中,在网络顶层的stride是32,这个对于像素级别的分割来说来太coarse了,作者使用了
hole algorithm来减少stride,保持feature map的视野。 - 论文中使用RPN来生成ROI。
- 总共有$2k(C+1)$个score map,C是类别数目,还需要考虑背景,2是对应了inside和outside。
- 使用
bounding box regression,对初始化的ROI做refinement,同时使用$1X1X4k^2$的filter,对bbox的shift和size做估计。
inference
- 使用RPN生成ROI,并保留其中score最高的300个ROI。
- 上述的300个ROI经过bbox regression之后,得到新的300个ROI。
- 对于每个ROI,都可以得到classification score和foreground mask
- 使用非极大值抑制,去除多余的ROI(那些重合度很高的ROI),剩余的ROI按照他们的
classification score进行分类。 - 对于当前的IOU,找到在600个ROI中与其IOU大于0.5的所有的ROI,foreground mask的类别对是所有ROI的mask进行逐像素的平均,再按照他们的
classification score进行加权。将average mask进行二值化之后输出,得到最终的foreground mask。
train
- 如果ROI与离他最近的groundtruth的IOU>0.5,则它就就被视为是positive的。
- 每个ROI都有3个loss:
- a softmax detection loss over C + 1 categories
- a softmax segmentation loss over the foreground mask of the ground-truth category only
- a bbox regression loss
后面2个loss只对positive ROI才起作用。
- 使用imagenet的pretained模型进行初始化,使用SGD进行优化。
- 对于RPN的proposal,使用9个anchors(3个尺寸,3个纵横比),coco多3个anchor(因为coco数据集的图像尺寸更加精细化,有很多很小的物体)。同时联合戌年FCIS和RPN,用于feature sharing。
实验和结论
- 作者做了大量的实验,包括对比MNC,结合InstFCN + R-FCN等,具体的实验结果见原文。这种方法赢得了coco2016分割比赛的第一。在coco detection上也是第二。