yolo及其V2与V3
yolo
- 之前在做目标检测的过程中,主要是2个阶段,首先生成大量候选框,然后再对候选框做分类,yolo直接使用端到端的方法,进行目标检测,实现了端到端的实时检测。
- 相对于其他比较主流的检测方法,yolo会出现更多的定位误差,但是误检测更少。
- yolo主要的步骤
- 将图像resize到$448 \times 448$
- CNN
- 使用NMS对输出的bbox做筛选,得到最终的检测结果。
- yolo在进行CNN的时候,使用的是整张图像,这与之前的
滑动窗口或者RPN的方法不同,它们只能看到图像的部分信息,因此yolo的background error比fastRCNN等方法要更小。
处理流程
- 将图像分成$S \times S$个grid cell,如果一个物体的中心落到一个grid cell中,则这个grid cell就
responsible for the object detection。 - 每个grid cell都用于预测B个bbox以及其置信度(confidence),最终的置信度的计算方式为$\Pr (Obj)*IOU_{pred}^{truth}$。$\Pr (Obj)$表示该物体为物体还是背景(0或1)。为背景时,置信度为0;为前景时,置信度为IOU。bbox用$(x,y,w,h)$,w和h都是相对于整张图像的大小,(x,y)是相对于grid cell边界的bbox中心的坐标。置信度就是预测的bbox与任意
gt bbox的IOU。 - 每个grid cell会预测得到物体属于类别C的条件概率。不管这个grid cell中有多少个预测的box,只对每个grid cell预测一组属于类别C的条件概率,即我们假设每个grid cell中只属于一类。将条件概率与之前的$Pr(Obj)$相乘,我们就可以得到grid cell属于某个类别的置信度。
- 每个box都会用5个变量来表示,每个grid cell中会预测出属于C个类别的概率,因此最终得到的tensor是$S \times S \times (B*5+C)$维的tensor。
网络设计
- 使用CNN做特征提取,最后加上FC层,做类别预测与bbox回归,CNN借鉴了
GoogLeNet的思想,但是稍微修改了其中的inception modules,在3X3的卷积层使用1X1的reduction layer(将feature layer缩减为1层) - 在imageNet的分类任务上与训练卷积层,其尺寸是$224X224$的,因此之后再将分辨率提升一倍,用于论文中的目标检测。
训练
- 使用leakyRelu作为激活函数。loss为bbox预测的loss和class的loss,在实验中发现两者如果权重相等, 容易造成模型不稳定,因此调整了一下2个loss对整体的影响。赋予2个loss不同的权值。最终的loss为
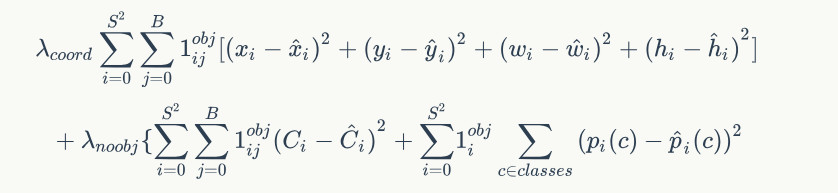
其中$1_{i}^{obj}$表示第i个grid cell中是否有物体;$1_{ij}^{obj}$表示第i个grid cell中的第j个bbox是否responsible for the object detection(前面提到的,物体中心落在这个bbox中,就responsible for the object,跟grid cell的responsible相似,这里不知道怎么翻译2333)
测试与结论
- 对于pascal voc数据上的图像,每张图像会生成98个bbox,在grid cell的边界处,可能会生成很多个检测的结果,这种问题使用NMS(非极大值抑制)就可以解决。
- yolo速度很快,这是他最大的优势,同时精度也没有下降很多(与非实时的那些算法相比)。
- yolo在每个grid cell中只预测两个bbox,而且一个grid cell只能有1个类,因此对于那些小物体或者一个grid cell中有多个物体,或者一个grid cell中有不同的物体的情况,yolo的表现都不是很好。
- 相对于fasterRCNN等方法,yolo的background mistakes要小很多,但是localization mistakes要大很多。
yoloV2
- 之前的yolo中,只能预测20类的物体(针对pascal voc),yolov2更快更好,可以达到实时,精度也是state-of-art。67FPS时,在VOC2007上,mAP达到了76.8%,40FPS时,mAP达到了78.6%,这比SSD,FasterRCNN等都更快,而且精度更高。同时基于yolov2,也提出了yolo9000,可以检测超过9000类的物体,提出了一个新方法,用于对物体分类与检测同时训练。使用coco检测数据集与imagenet分类数据集进行训练,之前的yolo只能预测200多一点的类别,yolov2可以预测超过9000个类别。
better
- 相对于其他主流的检测方法,之前的yolo有几个比较明显的缺点。
- yolo的localization mistake比较大
- 相对于基于RPN方法的检测算法,yolo的recall比较低。
- 作者使用
batch normalization,去除了dropout,提升了模型的准确度,同时也没有造成过拟合。 - yolo中是使用$224 \times 224$的图像做训练,yolov2直接使用$448 \times 448$的图像做训练(后面提到为了使得feature map有唯一的中心,将图像减小至416),这提升了模型的分辨率,有利于检测。
- 借鉴FPN中
anchor box的概念,之前的yolo是直接预测bbox的信息,而FPN是预测bbox相对于anchor box的offset,因而使得网络更容易训练。 - yolov2中去除了FC层,使用anchor box去预测bbox;去除了一个pooling layer,使得输出结果的分辨率更高。将图像减小至$416 \times 416$,使得最终的feature map有唯一的中心(输出的feature map有唯一的中心)。最终feature map的大小为$13 \times 13$。
- yolov2中,对于每个anchor box,都单独预测他们的类别以及是否属于物体(或者是背景)的概率。使用这种anchor box的方法,模型的mAP略微下降了一些(69.5->69.2%),但是recall有了很大的提升(81%->88%)。
- 作者使用了
dimension cluster的方法,之前的anchor的大小都是手动设定的,在yolov2中,作者对训练集的bbox使用kmeans聚类的方法,去找到好的先验框。距离度量方法使用IOU的距离度量(如果使用欧式距离,则大的box会比小的box产生更大的聚类误差)。
$$d(box; centroid) = 1 − IOU(box; centroid)$$
作者做实验,得到更大的k会导致更高的IOU,但是这也会使得模型变得更加复杂,最终取k=5。这一步主要基于的假设是:使用与正确的box尺寸更加接近的box去做预测的时候,会使得训练更加容易。
假设box的参数为$b_x,b_y,b_w,b_h$,先验box的大小为$p_w,p_h$,则我们使用下面的方法对$t_x,t_y,t_w,t_h,t_o$进行预测。其中$c_x,c_y$是grid cell的尺寸。
$$\begin{array}{l}
{b_x} = \sigma ({t_x}) + {c_x}\
{b_x} = \sigma ({t_x}) + {c_x}\
{b_w} = {p_w}{e^}\
{b_h} = {p_h}{e^}\
\Pr (obj)*IOU(b,obj) = \sigma ({t_o})
\end{array}$$
- fasterRCNN与SSD等都是通过在不同的feature map上使用proposal network,实现对不同尺度的物体的检测,而yolov2中,直接将$26\times 26$的feature map通过passthrough layer传递到最后,实现对细粒度物体的检测。具体方法:将$26 ×26×512$的feature map直接转化为$13\times13\times2048$的feature map,再与最后一层做concatenation。
- 作者在多个不同的尺寸下进行了训练。
faster
- 提出了新的分类模型作为yolov2的base network,称之为
darknet-19。其中有19个卷积层,5个最大池化层(卷积层不减小feature map的尺寸,max pooling每次减小一半)。
stronger
- 作者提出了一种将分类和检测进行联合训练的方法,在训练的过程中,如果它是用于检测的图像,则BP的时候,会计算yolov2的loss,如果是用于分类的图像,则在BP的时候,只返回用于分类的那部分的loss。
- 这种架构也可以被用于更多种类的物体的分类与检测,即作者提出yolo9000,在这里就不详细展开了。
yolov3
- v2对小的物体的检测效果还是一般,因此v3中对其又做了一些改进
Bounding Box Prediction
- 这一步骤和v2中的相同,在计算loss的时候使用SSE,因为更加方便计算。
- 使用logistic regression对bbox是否属于object进行预测,如果一个prior box与gt box的IOU大于其他所有的prior box与gt box的IOU,则该prior box的值为1。
- class prediction:之前使用的是softmax,这种进行multilabel的预测时,某个label的值会抑制其他label的值,因此v3使用logistic classifier。
- v3在三种不同的尺度上进行bbox的预测,在每个尺寸上,都预测3个box,因此每个尺度上输出的tensor是$N \times N \times [3 ∗ (4 + 1 + 80)]$,80是类别数,1是是否为物体(或者是背景),4表示bbox的预测。
- 将当前feature map经过上采样,提取浅层网络中的feature map,与经过上采样的feature map做concatenation,这有利于获得图像的语义信息以及细粒度的信息。
- v3中仍然使用kmeans用于确定prior box的尺寸(9个cluster)。
- Feature Extractor:作者采用了一个新的网络结构,因为有53层卷积层,因此命名为
darknet-53。这个在分类任务上精度可以与ResNet-152媲美,但是速度要快一倍。
尝试过但是没有用的
- 对anchor box的x,y偏移使用线性激活函数做基于box宽高倍数的预测,但是最后发现效果不好,而且模型不稳定。
- 使用线性预测而非logistic预测直接预测anchor box的x与y,发现模型的mAP会下降一些。
- 想使用focal loss,发现这种方法也会使得mAP下降。
- Dual IOU thresholds and truth assignment:fasterRCNN在训练中中使用双边IOU阈值,大于大的阈值被视为正例,小于小的被视为反例,在这之前的不做处理。在v3中使用了近似的策略,但是也没有取得很好的效果。