概览
- RCNN相关检测方法属于two stage的方法,跟yolo、SSD等
one stage的方法不同,它是首先得到proposal,再对其进行regression与classification。比较经典的论文有RCNN、fast-RCNN、SPP Net、faster RCNN等。当然也衍生出许多其他的方法,在这里主要对提到的几篇论文及其方法做一个大概的总结。
RCNN
主要思路与方法
- detection与classification不同,他不仅需要知道物体的类别,还需要知道物体的位置。
- 作者将detection的定位问题视为一个回归问题,之前也有一些基于类似的思路展开的工作,但是效果很差。
- 跟之前的基于传统特征不同(HAAR、HOG等),论文使用了CNN进行特征提取,同时与之前的基于滑动窗口的proposal生成的方法不同,论文使用了
Selective Search方法生成1k~2k个proposal(候选框),在此基础上进行特征提取。 - RCNN对CNN提取的特征使用SVM进行分类,同时使用bounding box regression对bbox进行finetune,最终得到检测结果(bbox+classification)。
bounding box regression的讲解可以见该博客:https://blog.csdn.net/u012526003/article/details/82155937
contribution
- 在detection任务中提出了基于CNN的特征提取的方法,引入了
bounding box regression,同时使用Selective Search代替传统的滑动窗口的方法。 - RCNN中,没有实现CNN的参数共享,因为每个proposal都会单独使用CNN提取一遍特征,这在后续的工作中得到了解决。
SPP Net
主要思路和方法
- 之前的CNN方法中,要求图像是固定大小的,这样CNN才能进行正常的信息传输,论文中提出了一种空间金字塔池化的方法,可以将任意大小的图像作为CNN的输出,经过SPP layer之后变成相同大小,这样可以保证最后fc层的输入是固定大小的。
- SPP layer的可视化举例如下
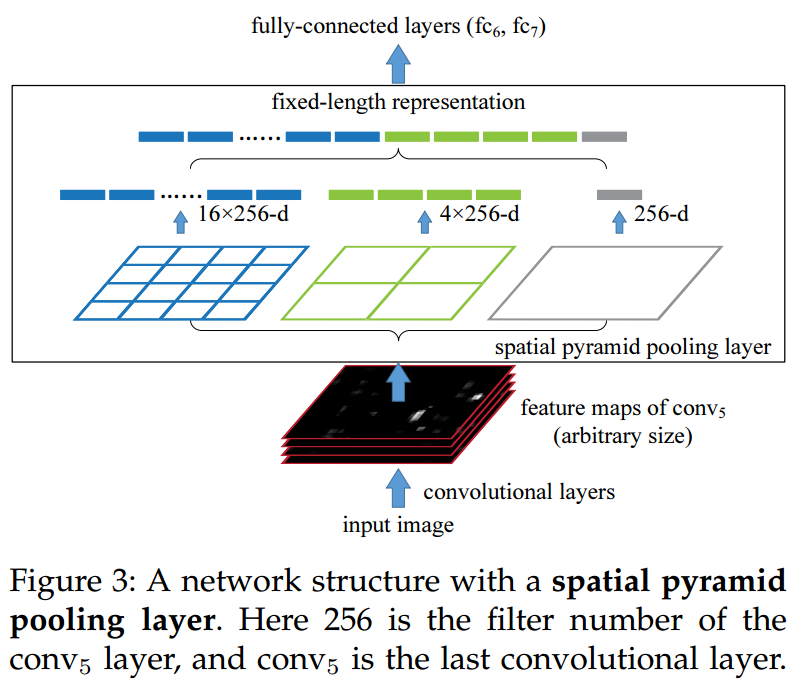
不管图像尺寸多大,首先经过CNN,得到feature map,对这个feature map做空间金字塔池化,将不同金字塔的池化结果(max pooling)做concatenation,最后形成一个固定维度大小的feature,这样就可以作为fc层的输入了。
- 使用SPP net,可以同时检测大物体和小物体(设置不同的池化尺寸即可),同时不需要对图像做crop或者resize,从而避免了信息损失和物体变形的问题。
与RCNN的区别与联系
- SPP-Net与RCNN都是首选使用
Selective Search生成候选框。 - RCNN将proposal缩放到固定大小,再输入到CNN中提取特征,因此十分耗时(有需要feature都被重复计算了);而SPP-Net是将整张图像输入到CNN中提取特征,然后在proposal在feature中对应的位置使用
SPP layer提取特征,因此减少了大量的CNN feature的计算。 - 最后也是基于SVM进行分类。
fast RCNN
主要思路与方法
- fast RCNN相对于RCNN,训练和测试时间大大缩减,它对整张图像只需要提取一次CNN feature。
- fast RCNN的输入是RGB图像以及一系列的proposal,proposal可以通过
selective search方法生成。 - 提出了Roi Pooling的概念,将不同proposal的中的feature map(大小不同)经过
RoIPooling layer处理之后变成统一的大小。 - 引入了多任务的loss,使得整个训练过程是
single stage的。对于分类loss,使用softmax loss,对于bounding box regression的loss,使用Smooth L1 loss,具体概念可以见:https://blog.csdn.net/u012526003/article/details/81609096。上述2个loss加权和就是整个任务的loss。
contribution
- 相对于RCNN,SPP-Net大大缩短了训练与测试时间,但是仍然有一些比较明显的缺点:整个过程十分复杂(多个步骤),同时也需要将CNN feature写入到硬盘中,用于后续的分类任务。相对于这2个工作,fast RCNN有以下优点:
- 比RCNN与SPP-Net的mAP更大。
- 使用多任务loss,使得整个任务的训练是single stage的。
- 训练过程可以更新所有网路的参数(之前都是单独训练的)。
- 不需要磁盘空间去存储特征。
- 最主要的几个点:
shared CNN feature+RoI Pooling+Multi task loss。
其他值得借鉴的地方
- 论文中作者也做了很多其他的实验,比如说SS生成的proposal的数量对结果的影响,数据增强方法等,这都对神经网路的设计与学习有比较好的思考,具体可以看论文。
faster RCNN
主要思路与工作
- 之前的proposal都是需要使用一些方法去生成,比如说
Selective Search等,faster RCNN则是提出了region proposal network(RPN),使得候选框生成的过程也被集成到整个网络中,使得整个任务的pipeline更加简洁。 - 整个detection任务的示意图如下
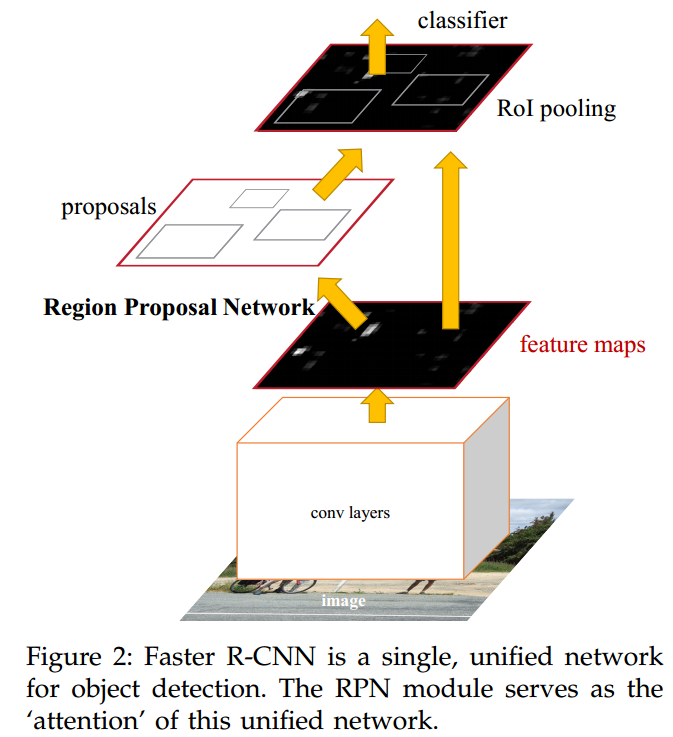
首先也是使用CNN提取CNN feature,在feature map上的每个点生成proposal(每个点生成9个,3 scales与 3 aspect ratios)。RPN可视化如下
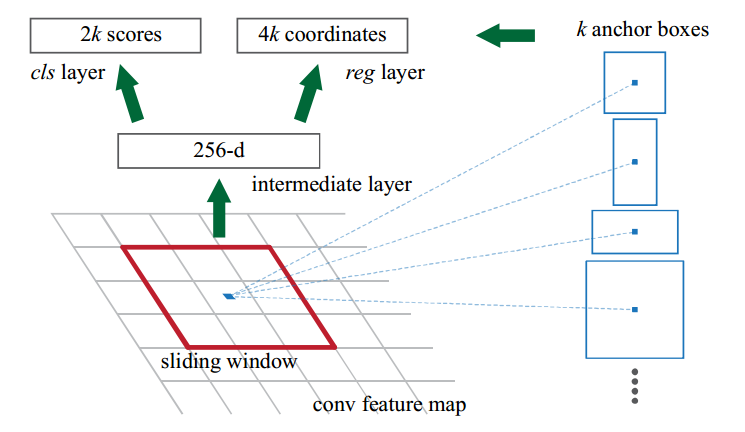
假设每个feature layer的生成滑动窗口的位置都产生$k$个anchor box,因此会生成$2k$个分类结果(每个box都有是物体以及不是物体的概率)以及$4k$个score结果(box的xywh信息),之后使用bbox regression获得精确的proposal。该步骤的loss是二分类的loss(proposal是否为物体)以及proposal的bbox regression loss。
- 对proposal在feature layer中的对应部分经过RoI Pooling,之后送入fc层用于判断物体的类别。
- 使用softmax loss训练proposal feature layer进行分类,同时使用bbox regression再次修正anchor的位置。
- 论文中使用了
4步训练的方法- step1:训练RPN
- step2:基于step1中生成的proposal,基于fast RCNN模型去训练一个detection network。
- step3:使用detection network对RPN进行微调,在这里固定shared CNN layers,只对那些只属于RPN的网络参数进行finetune。
- step4:固定shared feature layer,对只属于fast RCNN的CNN layer进行finetune。
- 得到最终的模型。
contribution
- RPN
- training method