SegNet
- 论文地址:https://arxiv.org/pdf/1511.00561.pdf
Abstract
- 提出了一个用于语义分割的
encoder-decoder的网络结构,encoder用于特征提取,decoder用于将feature map恢复到原始图像大小,从而实现像素级别的分类。 - 在max pooling时,记录下最大值所在的index,在unpooling时,使用该index进行值的恢复,但是这样得到的feature map是稀疏的(每4个数中有3个都是0),因此使用convolution kernel,得到dense feature map。
- 因为SegNet是为场景理解而设计提出的,因此它在inference时的时内存与计算时间都很efficient。
introduction
- SegNet的encoder结构与VGG16是完全相同的。
- 在decoding过程,使用在max pooling时记录的index有几个好处
- 提升了对边界的描述的准确度
- 减少了在端到端训练过程中需要学习的参数量。
- 这种方式易于扩展到其他的
encoder-decoder结构中。
- 之前也有这种基于max pooling index的decoder的工作,但是它也加上了fc layer,fc layer的参数占了总体90%的参数量,这也使得训练过程比较困难。
architecture
- SegNet architecture如下
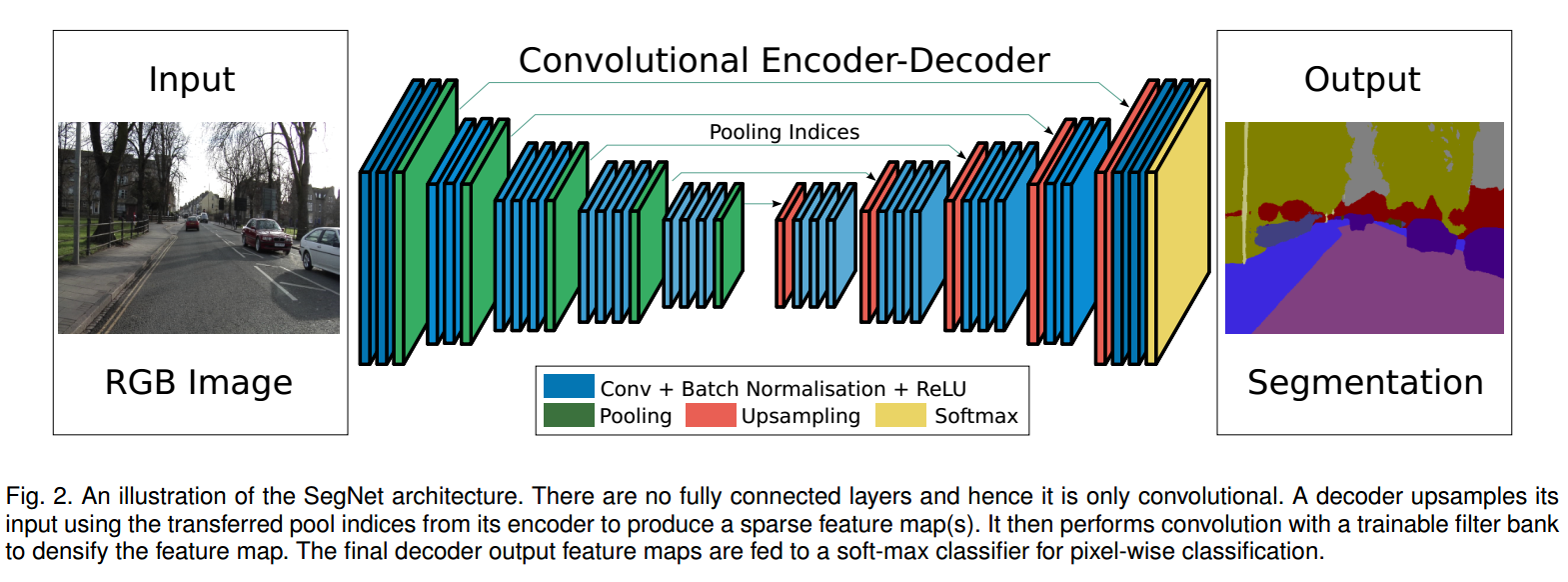
- 需要注意的是,在每次convolution的时候,使用了
CNN+BN+RELU的组合。 在降采样的过程中,feature map逐渐减小,这会损失边界信息,记录max pooling过程中的index,可以较好地捕捉到边界信息。SegNet使用2bits来存储$2X2$的max pooling的结果,这可以大大减少网络所需要的存储空间。SegNet中带有index的pooling如下图所示。
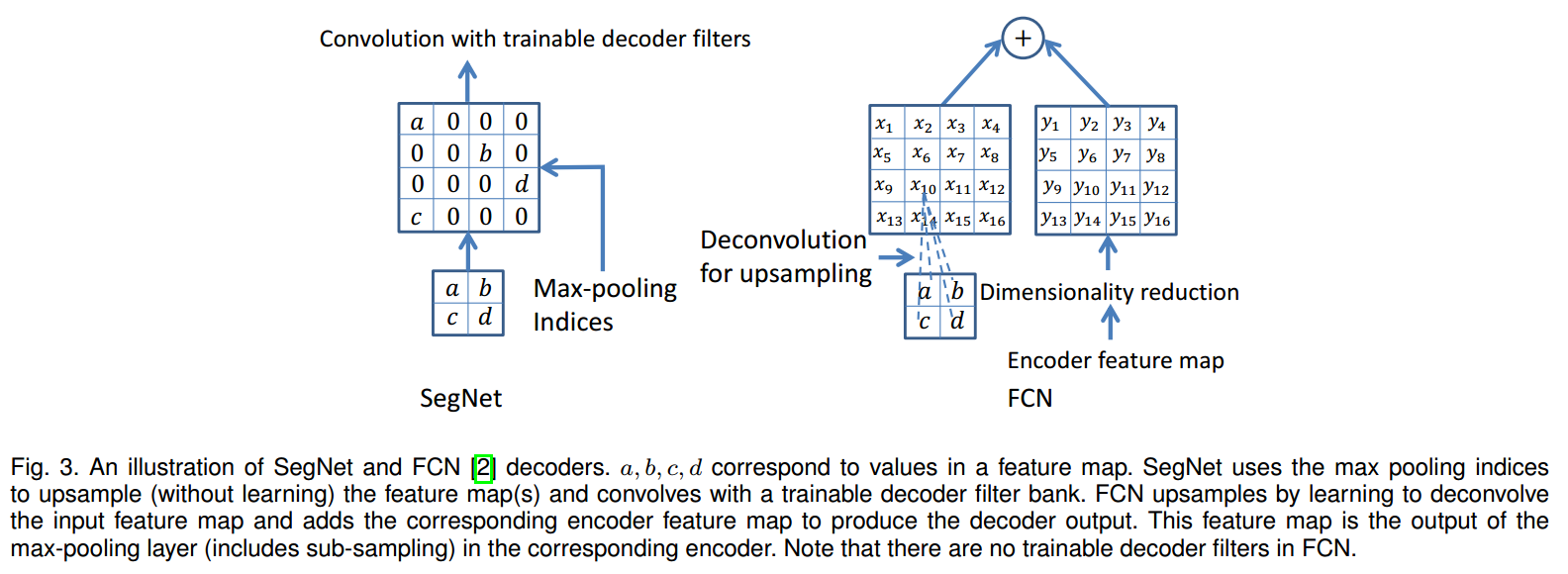
在decoder中,只根据之前记录的index去进行上采样,则unsampling得到的feature map中,每个都是有$3/4$的像素值为0,因此使用经过可训练的filter生成dense feature map。
- 在这里和DeconvNet与UNet进行了对比。
- DeconvNet参数很多,训练困难,需要大量计算资源。
- UNet没有使用带有index的pooling,同时去除了VGG中的Conv5以及pool5 layer,之后使用了deconvolution layer作为decoder。而SegNet使用了VGG-16中的所有参数作为pretrained weights。
- FCN中,在decode的过程中,会将上采样的结果与对称的encode的feature map相加,因此需要feature channel是相同的,而SegNet则不需要满足channel个数相同的条件。
- 经过对比实验,有几个关于SegNet的结论
- encoder feature map参数完全存储时,模型性能最好,这可以通过语义结果的边界看出来。
- 当内存要求有限制时,可以使用
降维或者max pooling index的方式减少内存要求,使用合适的decoder提升模型性能。 - 对于给定的encoder,更大的decoder会提升模型的性能。
benchmark
- 作者在2种场景下做了实验。
Road Scene Segmentation
- SegNet对小物体的分割更加准确,同时也会产生更加平滑的分割结果。
- DeconvNet和SegNet的IOU最高,但是SegNet的inference time比DeconvNet要少很多。
SUN RGB-D Indoor Scenes
- SegNet的mIOU比deeplab小一些,但是G,C以及BF指标都要更好。
- 这个任务比之前的任务要困难很多,主要是因为这里面的像素类别很多,类别不均衡现象更加严重,而且摄像头的视角不固定,物体的形状和大小变化比较多。
conclusion
- SegNet最主要的就是引入了这种
encoder-decoder的结构,同时使用带有index的max pooling的结构,大大减小了inference过程中的存储损耗(精度几乎不受影响)。 - 语义分割任务还有很大的提升空间。