DeepLab V1
- 论文地址:https://arxiv.org/pdf/1412.7062v3.pdf
Abstract
- 论文结合了CNN与CRF(条件随机场,属于概率图模型),CNN在high level属性上的预测效果很好,CRF可以带来更高的定位精度。
- 提出了
hole algorithm(孔洞卷积)。 - 在pascal VOC 2012的测试集IOU上达到了71.6%,排名第一。
methods
hole algorithm
- 以一维为例,
hole algorithm示例如下
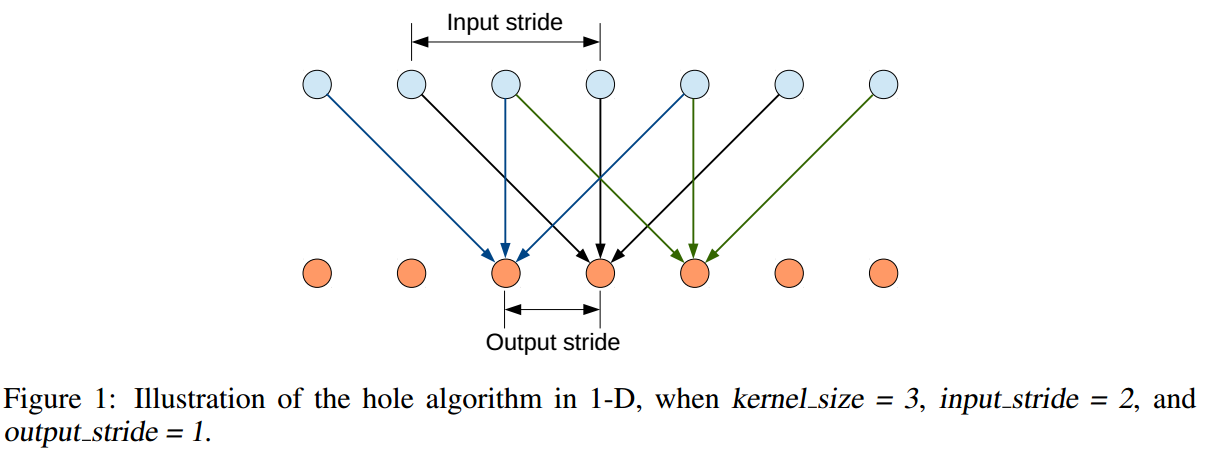
这种方法使得kernel较小的情况下,通过调整input stride,也可以获得较大的感受野。
- 在训练时,借鉴了VGG16,将最后的1000 FC layer换成了21 FC layer,使用VGG的预训练模型的参数,因为最后输出是下采样8倍,因此将groundtruth也下采样8倍,再设置loss为cross entropy loss,进行finetune。在测试的过程中,因为high level feature map变化十分平滑,因此直接使用双线性插值将feature map上采样到和原图相同的大小,这个步骤不需要训练,几乎没有计算损耗。FCN等全卷积网络因为没有采用
孔洞卷积,因此要想达到相同的感受野,需要下采样32倍,而要想恢复到原图大小,需要对上采样的参数进行学习(否则精度无法达到)。因此deeplab的CNN部分仅需要10h的训练时间,而其他的FCN可能需要几天时间。
模型respective field修改以及CNN计算时间优化
- 因为之前的fc layer中,计算量相对较小(VGG的第一个fc layer为1X1X4096),而改成fully convolutional layer之后,大小变成了7X7X4096,这大大增加了计算量和存储空间,因此将其size进行缩减,变为4X4或者3X3,减少参数量。
- 在之后的工作中,也提到了将feature channel数量减小来减少模型的尺寸。
detailed boundary recovery:FC CRF
- 之前的工作中有一个结论:更深的CNN可以得到更加准确的分类结果,但是定位精度会更低。解决这个问题有2种主要的方法:
- 将low level和high level的feature map进行融合,FCN就是这样做的。
- 引入
super-pixel representation,用low level segmentation method来进行定位任务。
- 论文中使用全连接的条件随机场方法来对定位做finetune,这比当前的方法都要更好。
- CRF之前就被用于平滑包含大量噪声的结果的工作中。
- 整个模型的pipeline如下:
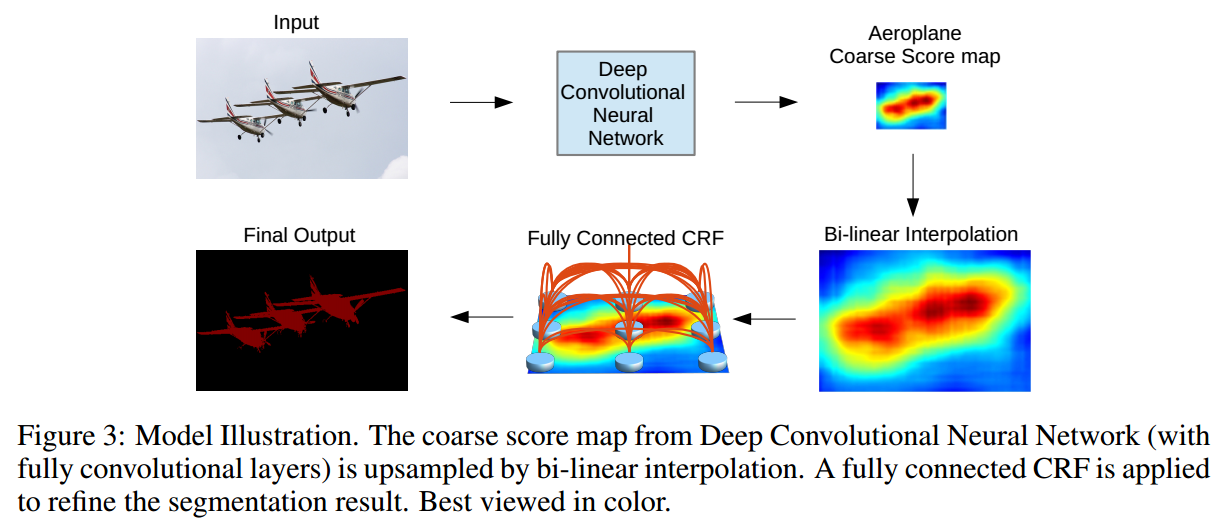
multi-scale prediction
- 使用多尺度预测,提供更加准确的分割结果:将输入图像通过2层的感知机,与前四层的pooling layer输出进行concatenate,再输入到softmax激活函数中,相当于softmax的输入channel是640。
evaluation
- 评测结果如下图,可以看出是直接秒杀当时其他state-of-art的方法。
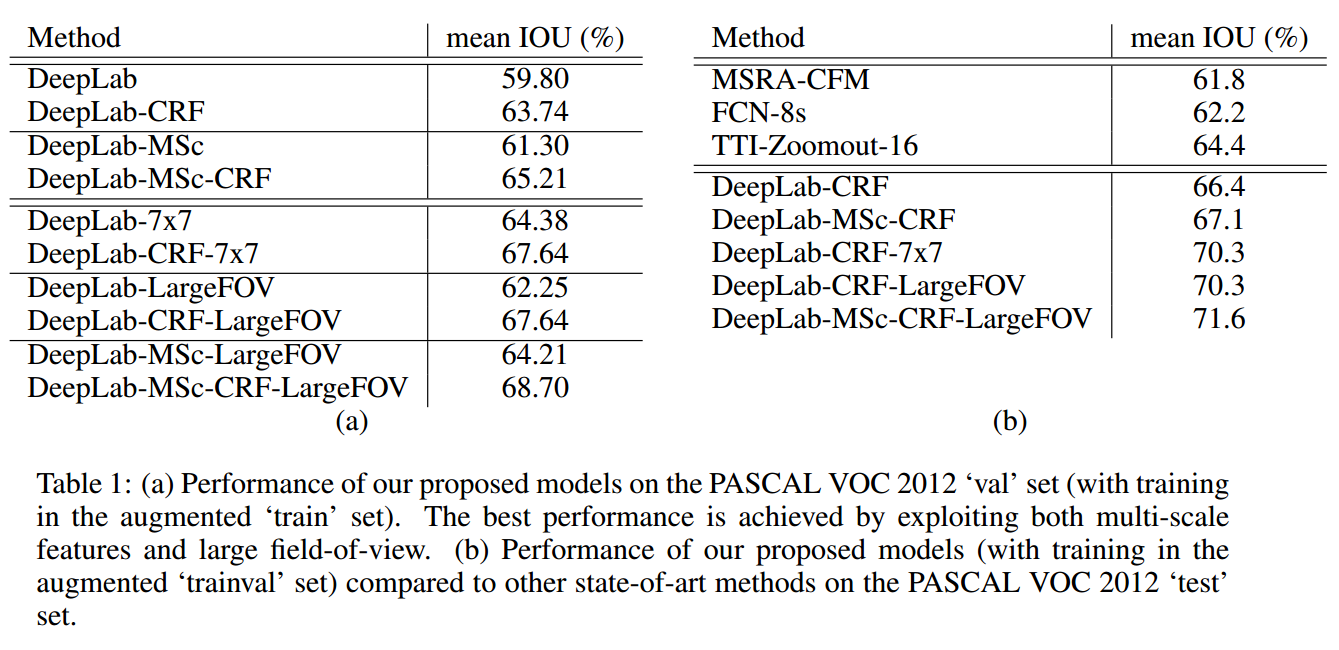
conclusion
- 论文最主要的点就是结合了CNN与CRF,在保证高分类精度的前提下,也保证了很高的定位精度。
- 引入孔洞卷积,在不要降采样或者增大kernel的情况下就可以增大feature map的感受野。
- 使用多尺度的方法进一步提升分割准确度。
DeepLab V2
abstract
- 使用
atrous convolution,即孔洞卷积,用于dense prediction,这个比其他的上采样方法效果要更好。 - 提出了atrous spatial pyramid pooling(ASPP),用于在多个尺度上对物体进行分割。
- CNN的帧率达到了8fps(CRF的帧率为2fps)。
- 使用CRF改进了分割边界的预测情况,提升了定位精度,这在Pascal voc 2012的测试集上达到了79.7%的mIOU(V1为71%),再次刷新分割的记录。
methods
atrous algorithm
atrous algorithm在一维上的可视化如下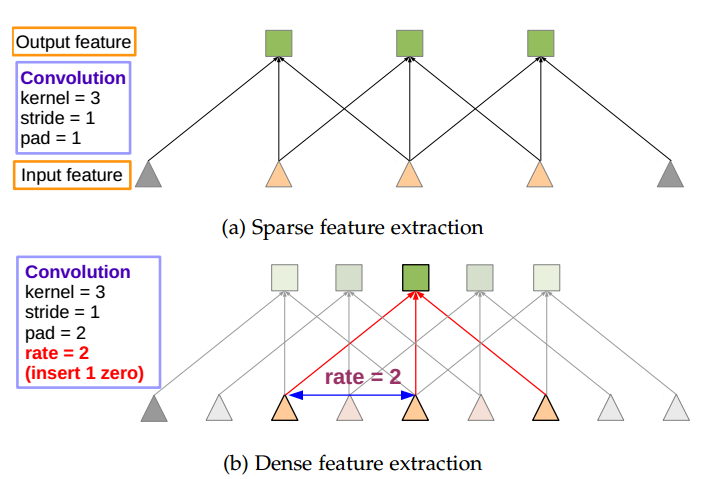
在扩大感受野的情况下,也没有引入多余的CNN参数。
atrous algorithm使得网络可以任意增大其感受野,而无需担心feature map尺寸无法恢复的问题。
ASPP
- ASPP示意图如下,使用不同尺度的atrous kernel做融合,实现多尺度信息融合,对特定像素点做分类。
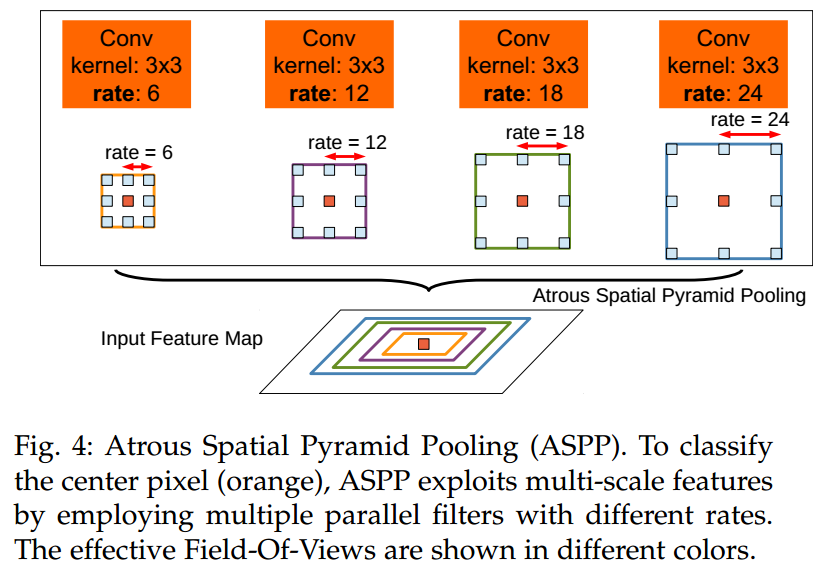
CRF
- 这个点在deeplab V1中就使用了。
evaluation
- 在V2中,有特定的学习率策略,作者发现
poly learning rate policy相对于使用固定步长降低学习率的方法来说更有效一些。公式如下
$$lr = {(1 - \frac {iter}{\max _iter})^{power}}$$
- 在验证集上的mIOU如下
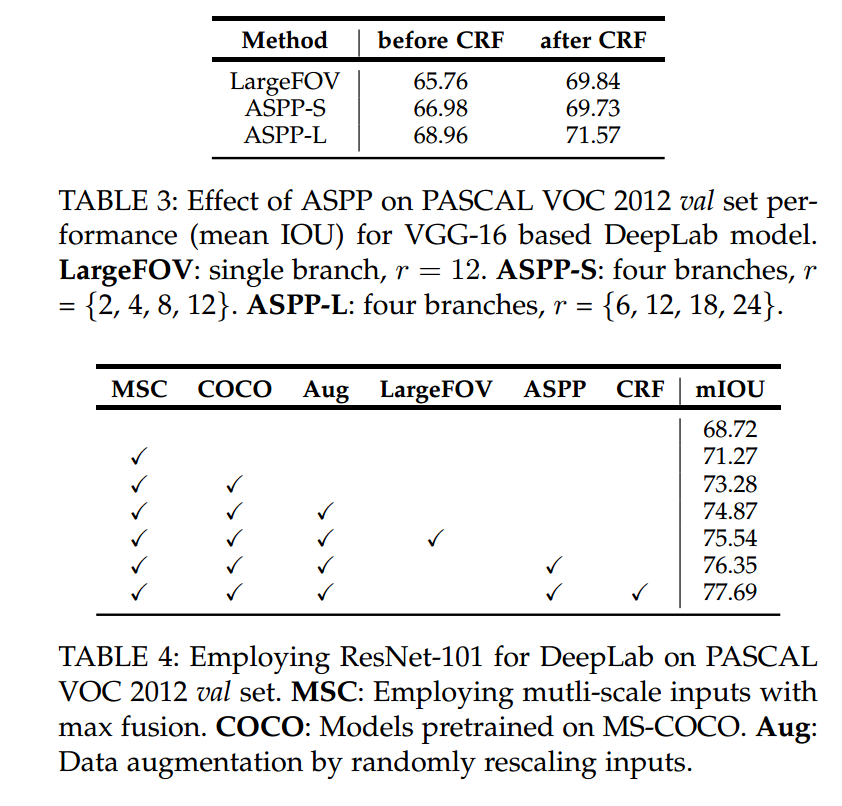
可以看出,ResNet的backbone大大提升了分割的mIOU。再贴一张在测试集上的表现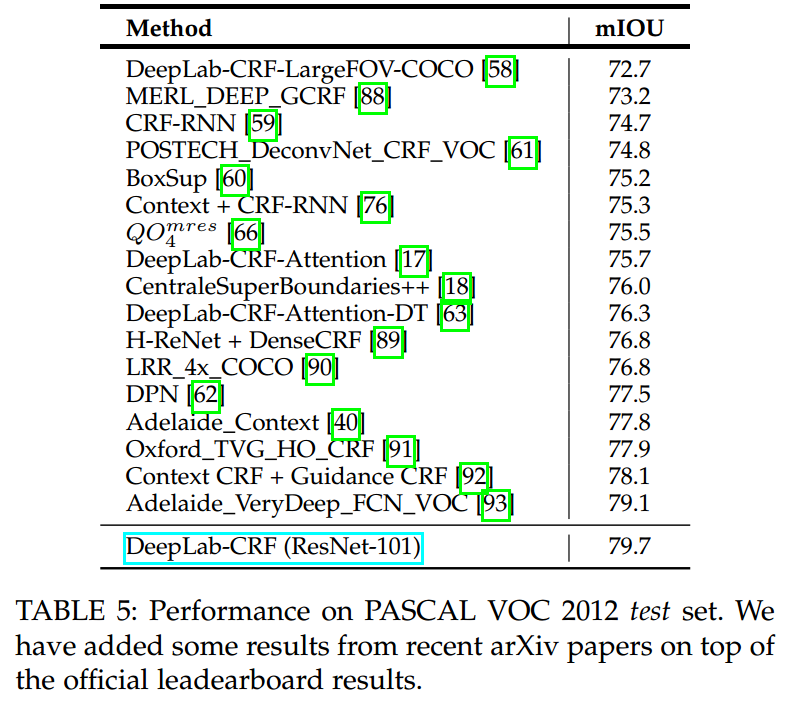
结果也是比state-of-art方法都要好。
- 作者也在其他数据集上做了实验,验证了模型的泛化能力。
DeepLab V3
abstract
- 基于前面的工作,继续探讨
atrous convolution,采用多个atrous rates,设计了一个将atrous convolution进行级联或者并行的模块,来实现多尺度的context信息。 - 改进了之前提出的ASPP模块,再次提升了模型性能。
- 公布了封装细节,分享了一些设计和训练经验。
- V3没有使用DenseCRF进行后处理,同样达到了state-of-art的水平。
related work
- 常用的用于捕捉多尺度信息的方法如下图
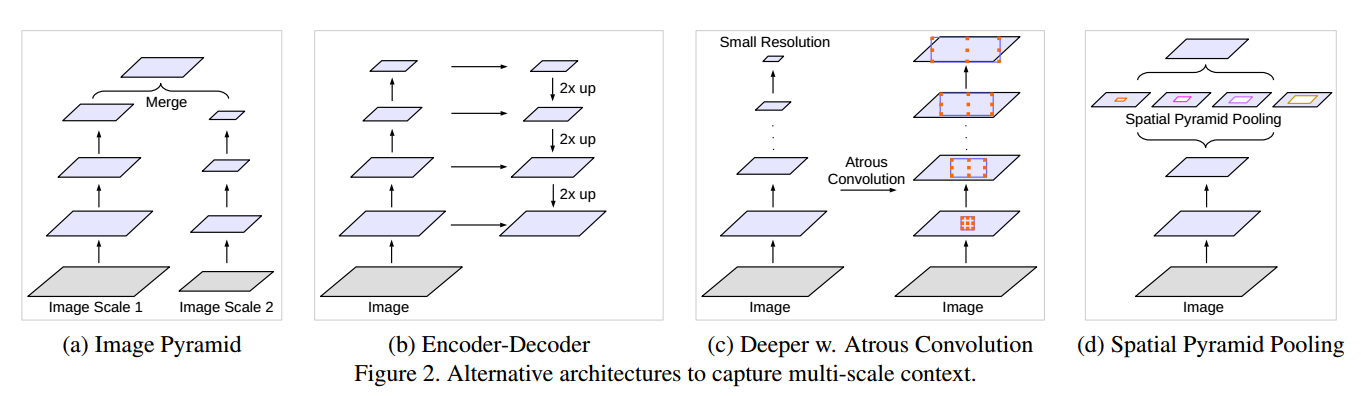
本文中主要是结合atrous与SPP,同时提出的这个模块可以用于任何网络模型框架中。
method
- review了之前使用的
atrous convolution。 - 使用multi-grid的方法,修改了resnet的block4~block7,使得他们的
output_stride都是16,这样就可以保证空间位置信息不会损失太严重,而且论文中也发现如果一直进行striding,会降低语义分割结果的准确度。加入atrous convolution的cascade模块如下,主要是使用了不同rate的atrous convolution进行操作,增大filter的感受野。
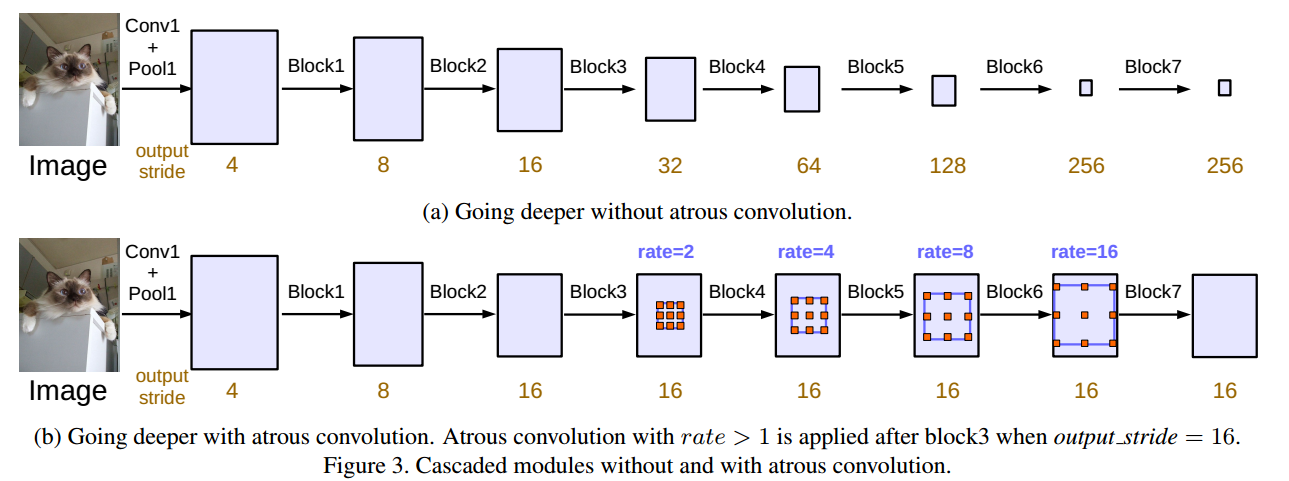
- 随着rate的增大,有效的权重逐渐减小,大部分的kernel最后都变成了1X1的kernel,因此在这里引入image level features,即在模型最后一层feature map上使用全局平均池化,同时引入BN,最后在双线性插值上采样的特定的尺度大小。最后再将ASPP结果和上采样结果做concatenate,经过1X1的CNN,得到最后的输出。整体流程图如下:
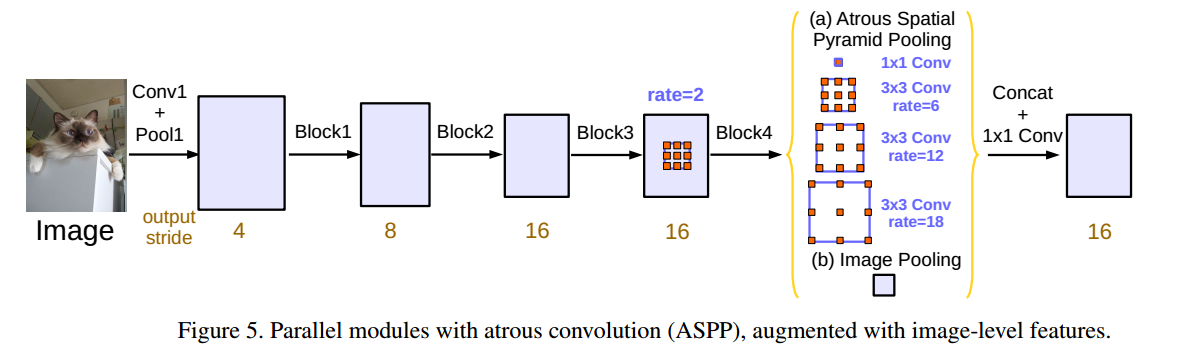
experiment and evaluation
training protocol
- learning rate和V2中的一样。
- cropsize:对图像进行裁剪,这是为了使得
atrous convolution在rate非常大时,其卷积数据仍然是有效的;如果不进行crop,在rate很大时,就需要用0做padding。 - batch normalization:BN需要较大的batch size才能体现出较好的效果,因此设置
batch size = 16 - upsampling logits:之前在训练时,是将groundtruth进行降采样,再计算loss,作者发现这样的话,会移除groundtruth的fine annotations,而且这一步骤是无法恢复的。因此在V3中,将CNN最后的输出做上采样再结合groundtruth计算loss。
- data augmentation:在训练时,对输入图像做随机scaling与left-right flipping。
evaluation
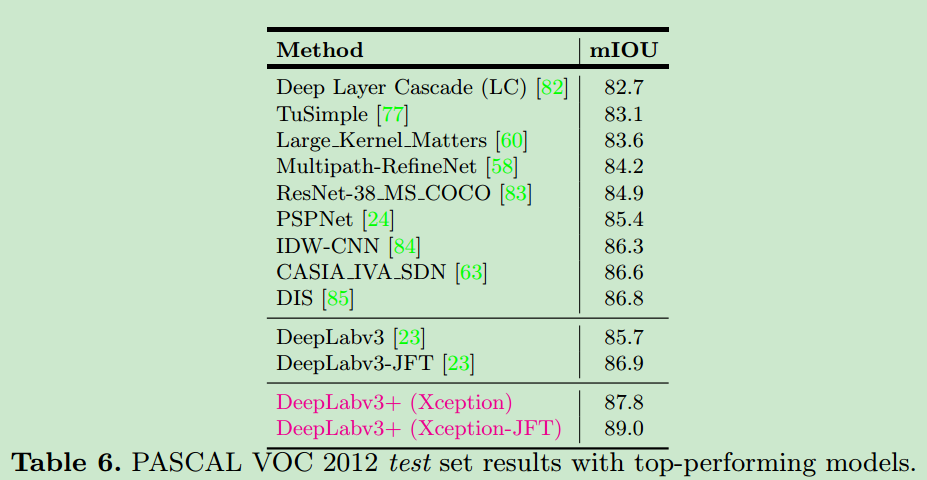
- V3在pascal VOC 2012 testset上的mIOU达到了86.9%,超过了所有其他的state-of-art的方法。
conclusion
- 主要就是将atrous convolution用于提取dense feature map,捕获long range context。
- 提出了cascade module,易于扩展。
deeplab V3 plus
abstract
- 语义分割常常使用
encoder-decoder的结构,encoder中使用SPP,提取多尺度特征,decoder中通过逐渐恢复feature map的尺寸,获取图像的边界信息。 - 论文中将Deeplab v3作为encoder,使用了一个简单有效的decoder,用于语义分割。
- 将xception用于特征提取,在ASPP和decoder模块中使用
depth-wise convolution,使得模型速度更快,准确度更高。 - 未加后处理的情况下,在pascal voc2012和cityscape上的mIOU达到了89%和82%。
contribution
- 提出了一个新的encoder-decoder结构,deeplab V3作为encoder,一个简单的模块作为decoder,如下图。
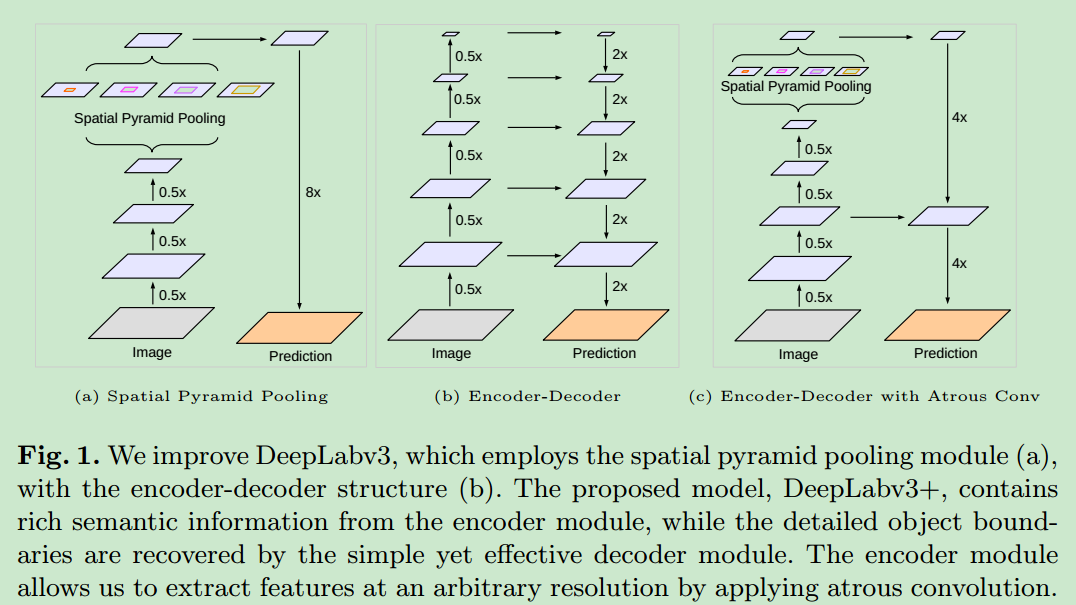
- 可以通过空洞卷积,任意修改在encoder中提取特征的分辨率(多尺度的信息),从而实现在效率和精度上的tradeoff,这在之前的encoder-decoder结构中是无法做到的。
- 将xception用于分割任务中,将
depthwise convolution用于ASPP与decoder结构中。 - 代码已经开源: https://github.com/tensorflow/models/tree/master/research/deeplab
methods
- 基于encoder-decoder的模块如下
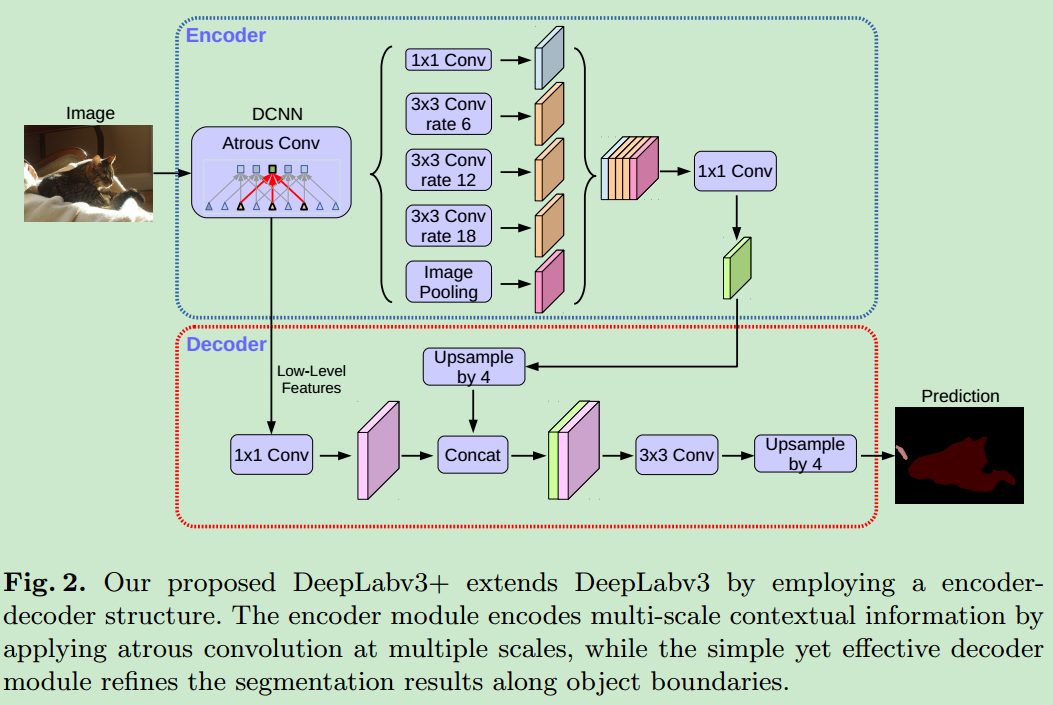
- 可以实现多尺度信息的获取。
Encoder-Decoder with Atrous Convolution
- 示意图如下
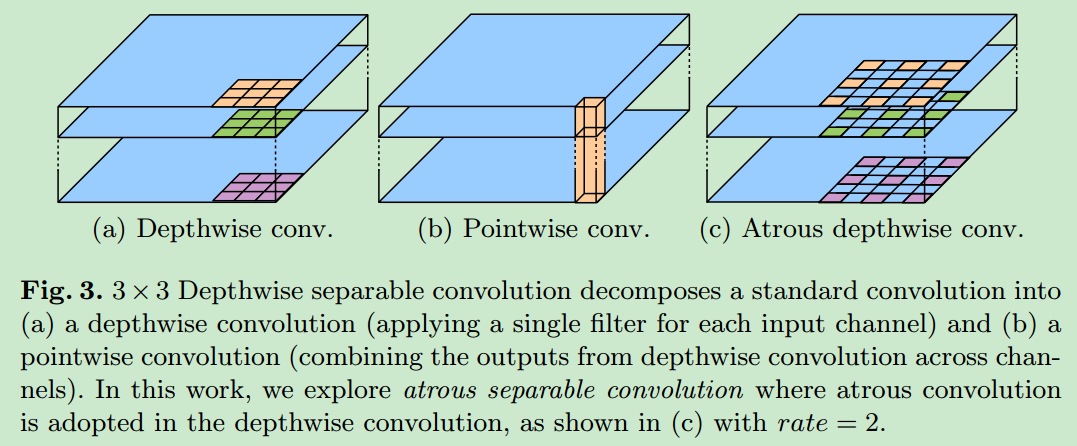
将传统的卷积转换为depthwise convolution以及当前的pointwise convolution,可以极大地加快模型的速度。
- decoder的
output stride调节容易,在分类任务中,可以调节为32,在分割任务中,可以调节为16或者8(需要更加准确的位置信息)。 - 之前的deeplab系列中,使用了双线性插值作为上采样的方法,将feature map恢复到原始图像大小,但是这个会损失图像的边界信息,因此论文中使用一个简单的decoder进行上采样的操作。在将low-level与high-level进行concatenation之前,首先将low-level feature map使用1X1 conv进行降维,减少计算量。
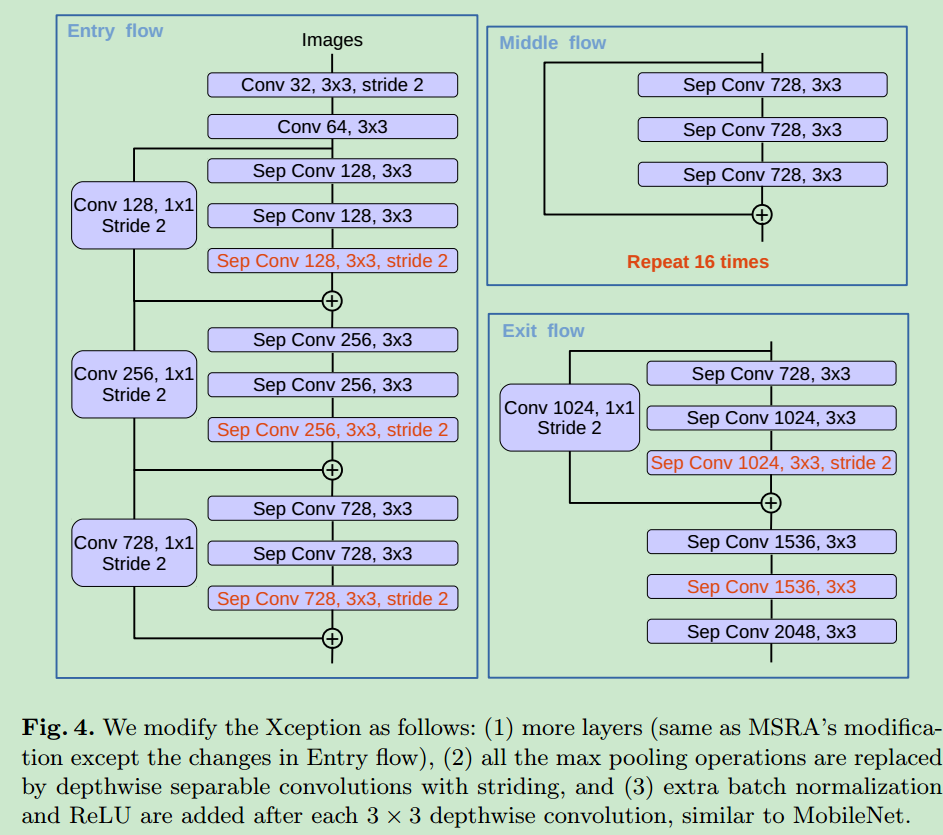
Modified Aligned Xception
- 基于之前的xception结构做了一些修改
- 所有的max pooling被修改为depthwise convolution with striding,这可以使得我们在任意分辨率上使用atrous separable convolution提取特征。
- 在每个3X3 depthwise convolution后面加上BN与RELU,这是参考了mobilenet结构。
- 修改后的xception模块如下所示。
experiments
Decoder Design Choices
- 修改了之前的双线性插值上采样方案,与Unet结构类似,设计了decoder结构,但是low level feature map首先经过1X1 convolution,降低channel的数量,之后再做concatenation。
- 考虑到GPU memory,没有考虑
output stride < 4的情况。
ResNet-101 as Network Backbone
- 主要是测试了channel数量和
output stride对计算量以及精度的影响。最后没有采用output stride=32的情况。
Xception as Network Backbone
- baseline:没有加decoder的情况,直接使用双线性插值上采样。
- Adding decoder:
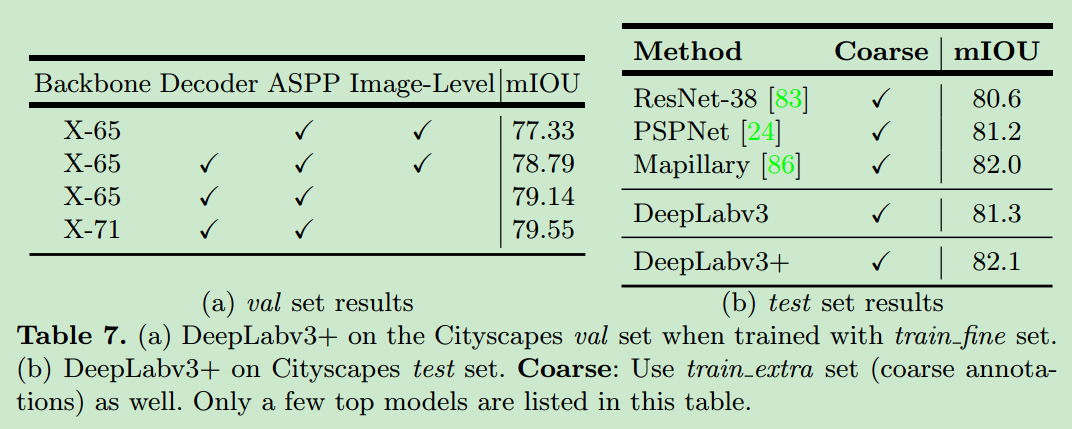
output stride=16的时候,加入decoder使得mIOU提升了0.8%左右。 - Using depthwise separable convolution:使用这个,计算量减小了33%~41%,mIOU没有明显改变。
- Pretraining on COCO:获得了2%的
- 提升。
- Pretraining on JFT:获得了0.8%~1%的提升。
- 模型对遮挡严重,相似度太高以及少见的类别的分割准确度不高。
results
- 在pascal voc2012以及cityscape上的表现如下
conclusion
- 基于deeplab v3提出了
encoder-decoder结构,decoder结构十分简单。 - 使用空洞卷积,可以在任意分辨率上提取特征(不降低feature map的size)。
- 使用改进的xception模块和atrous separable convolution提升速度和精度。
- 实验结果证明模型是很好的(state of art)。