FCN
- 论文地址:https://arxiv.org/pdf/1411.4038.pdf
Abstract
- 介绍了用于语义分割任务的全卷积的方法(其实这个在之前就出现过)
- 基于全卷积网络的CNN在语义分割任务中超过了state-of-art的效果(average IU比之前最好的结果高了20%),并且一张图像的inference time很短(0.2s左右)
- FCN是在之前一些用于分类的网络(Alex Net,VGG,Google Net)的基础上做finetune。
Fully convolutional networks
- 之前的分类任务是在CNN后面加上全连接层(fully connected layer),最后得到的是一个向量,可以表示为属于某个类别的概率;将fc layer替换为CNN之后,可以得到一个heatmap,这个heatmap可以反映某个特定像素所属的类别以及概率等。网络结构区别如下
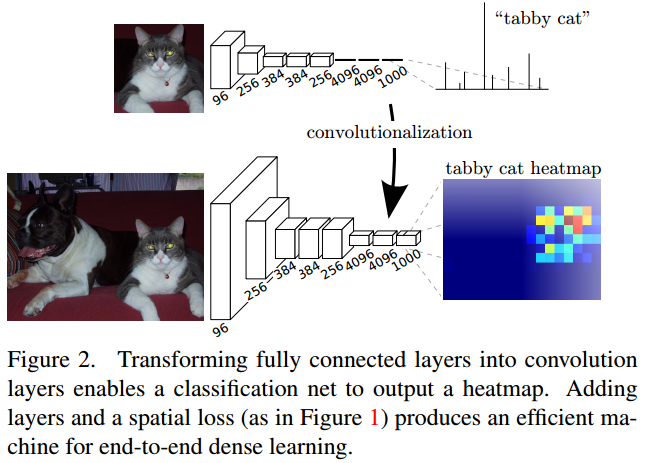
- 降采样会损失feature map的位置信息,但是会使得网络有更大的感受野。之前的想法是要想使得网络可以捕捉到更加精细的特征,需要减少网络中的降采样;但是本文中的工作表明,引入上采样以及
skip layer的结果可以避免降采样带来的信息损失。 - 上采样结构:deconvolution。上采样系数为f,表示以stride为1/f进行卷积。之前的卷积是多对一的关系,即一个kernel及其对应的感受野会得到一个输出,而现在是feature map上的一个点会影响输出feature map上大小为kernel大小的点,具体的可视化效果可以见链接:https://github.com/vdumoulin/conv_arithmetic
segmentation architecture
- 作者基于ILSVRC分类器,使用上采样和pixel-wise loss进行augmentation,得到了
dense prediction。之后又引入skip layer,将粗粒度的语义信息和细粒度的表观信息进行结合,对prediction进行refine。
From classifier to dense FCN
- 作者基于之前的分类模型,仅仅将最后的fc layer换成一个deconvolution layer以及1X1X21(20类+背景)的kernel做卷积,得到的结果就跟state of art类似(使用VGG net)。
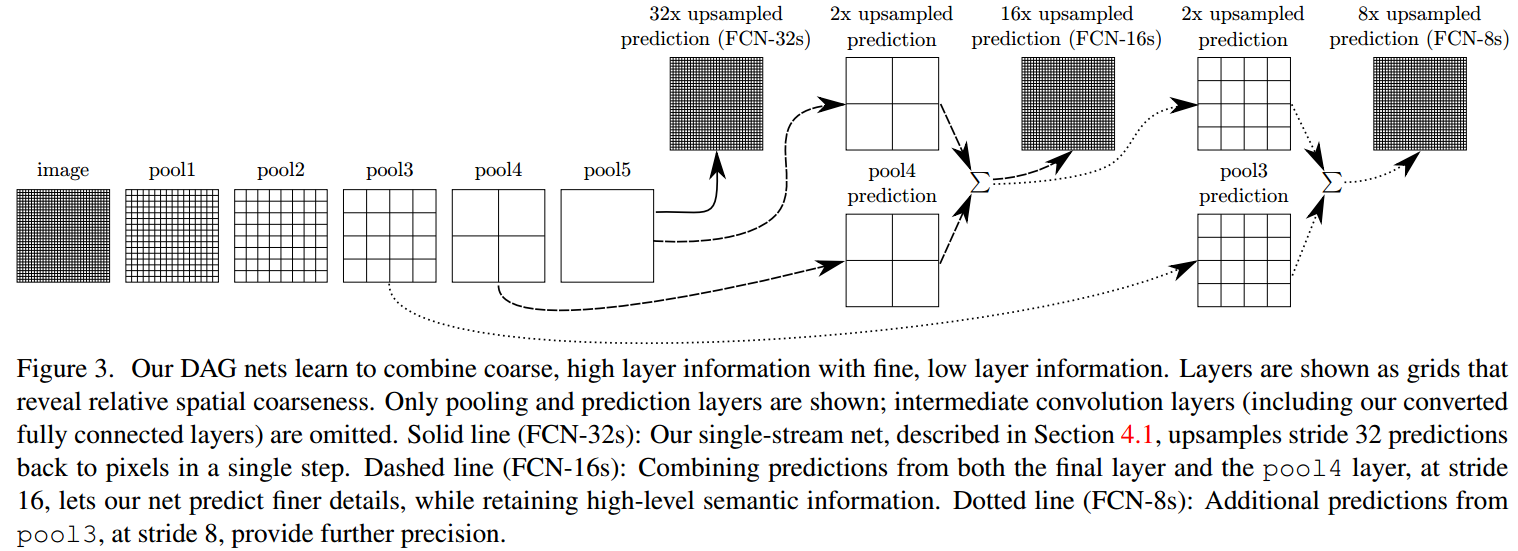
Combining what and where
- 浅层的feature map可以包含更多的位置信息以及appearance information,深层的feature map可以包含更加丰富的语义信息。
- FCN包含5个pooling layer,feature map尺寸降低了32倍,之后再使用32倍上采样,使得输出的feature map与原图大小相同,从而实现像素级别的分类。这个模型是
FC-32s。 - 将
pooling layer 4与2倍上采样的pooling layer 5相加,再进行16倍上采样,得到FCN-16s。 - 将
pooling layer 4与2倍上采样的pooling layer 5相加,再进行2倍上采样,与pooling layer 3相加,上采样8倍,得到FCN-8s。 - 具体的几个模型见下图
experiment, results and conclusion
- 作者为了提升模型准确度,在其他方面也做了一些尝试:class balancing,dense prediction,augmentation,more training data等,有些对模型准确度有提升,有些没有太大的帮助。
- 作者做了很多实验,验证了FCN超过了当前state-of-art的方法。
- 作者提出的FCN也为之后的语义分割等任务提供了一个新的思路,即直接使用CNN也可以做分类等任务,这也避免了模型的图像输入必须要求特定大小的问题。