NAS
- 论文地址:NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING
- 这篇文章是NAS的第一篇论文,在小的数据集上做了网络结构搜索优化,之后有很多论文都是基于这个思想,在分类、识别、分割等任务上做了一些尝试。
abstract
- 神经网络在视觉任务方面表现很好,但是需要手工设计良好的网络结构。在本文中,作者使用基于增强学习的RNN设计神经网络,主要有卷积网络与RNN结构。
- 论文的方法在
cifar-10数据集上表现超过了所有手工设计的网络结构,这是在神经网络搜索优化方面的初步探索,因此使用的数据集较小,
introduction
- NAS优化控制框图如下所示
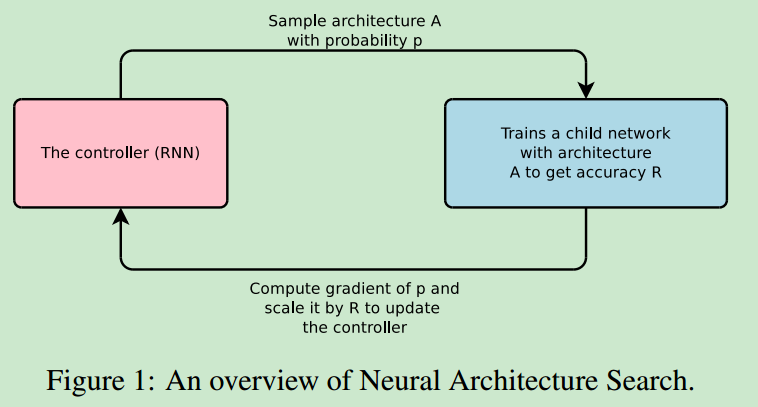
将模型的准确度作为reward,使用策略梯度更新控制器。对于准确度更高的结构,控制器会赋予其更大的概率。
- 关于超参数调节或者参数优化方面,之前有过较多的研究,比如说随机搜索、贝叶斯优化等方法,但是这些在网络结构搜索方面之前没有相关的工作。
- 论文中的控制器是一个
auto regressive的结构,即当前时刻的预测结果与之前的预测结果有关。
methods
卷积结构
- 首先介绍使用NAS生成卷积网络结构,下面是使用RNN去预测CNN结构参数的框图
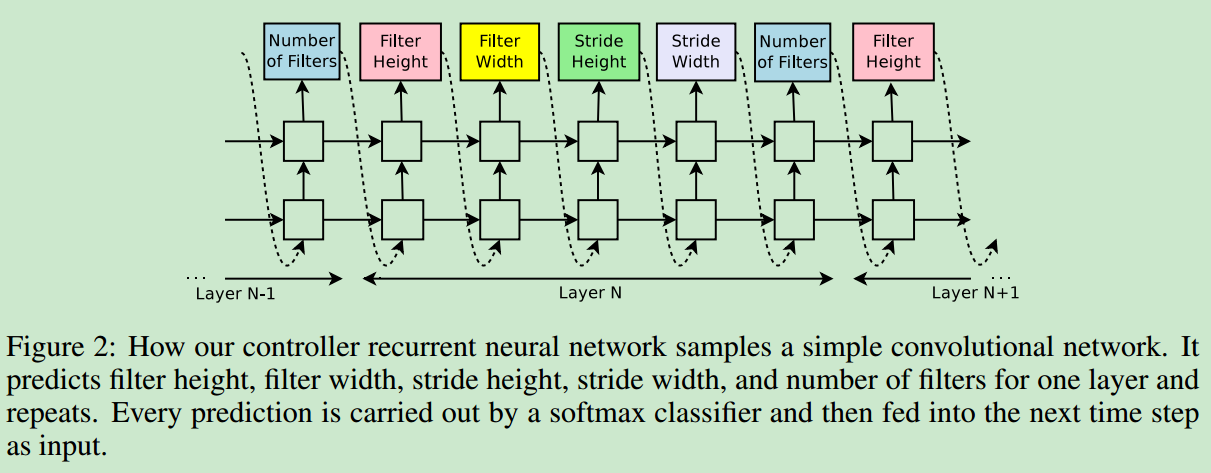
对于特定的网络层,依次预测filter height and width、stride height and width、 filter number,每个预测都作为下一个预测的输入,当网络层个数到达设置的阈值时,停止生成网络结构。使用增强学习的方法更新参数,具体的公式可以参见原始论文(我对增强学习不是很了解,在此就不给出具体的公式了)。
skip connection
- 之前的搜索空间中不包括
skip connection结构,在这里介绍了一种可以引入skip connection的方法。如下面的公式
$$P\left( {Layer \; j \; is \; an \; input \; to \; layer \; i} \right){\rm{ }} = {\rm{ }}sigmoid({v^T}tanh({W_{prev}} {h_j} + {W_{curr}} {h_i}))$$
使用这种方法,计算特定层是否被引入到当前层的计算的概率。这与传统的残差结构不同,同时可能有多个之前的feature map进行concatenation之后作为当前的输入。
RNN结构预测
- 这里没有细看,不作解读。
result
- 贴一张NAS生成的结构在cifar上的性能。
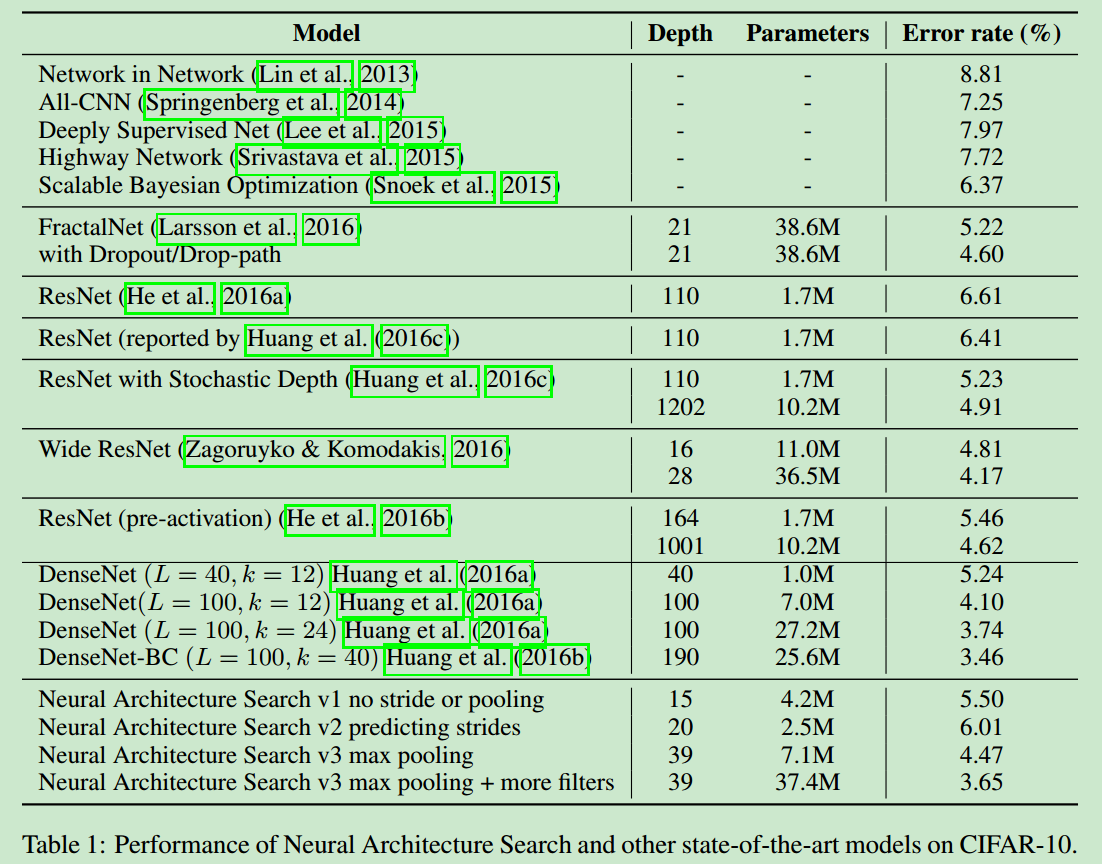
NasNet
abstract
- 模型结构至关重要,论文提出了一种直接在感兴趣的数据集上进行模型结构设计的方法,使用
architectural building block,再利用这些blocks去生成最终的模型。 - 论文主要的贡献就是设计了一种新的搜索空间:
NASNet search space,其迁移性也很好。 - 介绍了一种新的正则化方法:
ScheduledDropPath,这提升了NasNet的泛化能力。 - 设计的模型在imagenet上的性能超过了最好的人工设计的模型,在coco数据集上也超过了state of art的性能。
introduction
- 如果直接使用NAS在大的数据集上搜索最好的网络结构,则计算量太大,论文中首先在
proxy dataset上搜索好的模型结构,在将其迁移到imagenet上。 - 论文中通过设计搜索空间来实现这种良好的迁移性能,从而使得模型结构的复杂度与网络深度以及输入图像大小无关。即:搜索空间中的CN结构都是由convolution layer(cell)组成,他们的结构相同,权重不同。
这在大大提升搜索速度的同时也可以提升模型的泛化能力。
method
- 在cifar和imagenet上的网路结构如下图
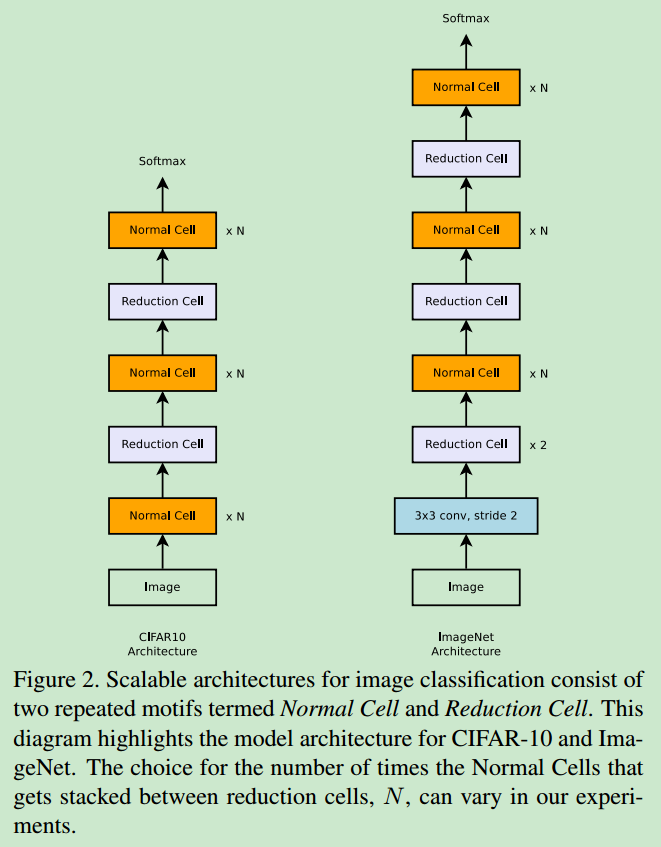
主要包括normal cell与reduction cell2种cell。normal cell前后的feature map size相同,经过reduction cell后,feature map的宽高会减半,从而增大感受野。
- 一个blcok的生成步骤为:选择之前两个输出层,选择两个操作对其进行转化,再选择一种方法将两个输出结合成一个输出,得到当前block的输出。结构框图如下所示
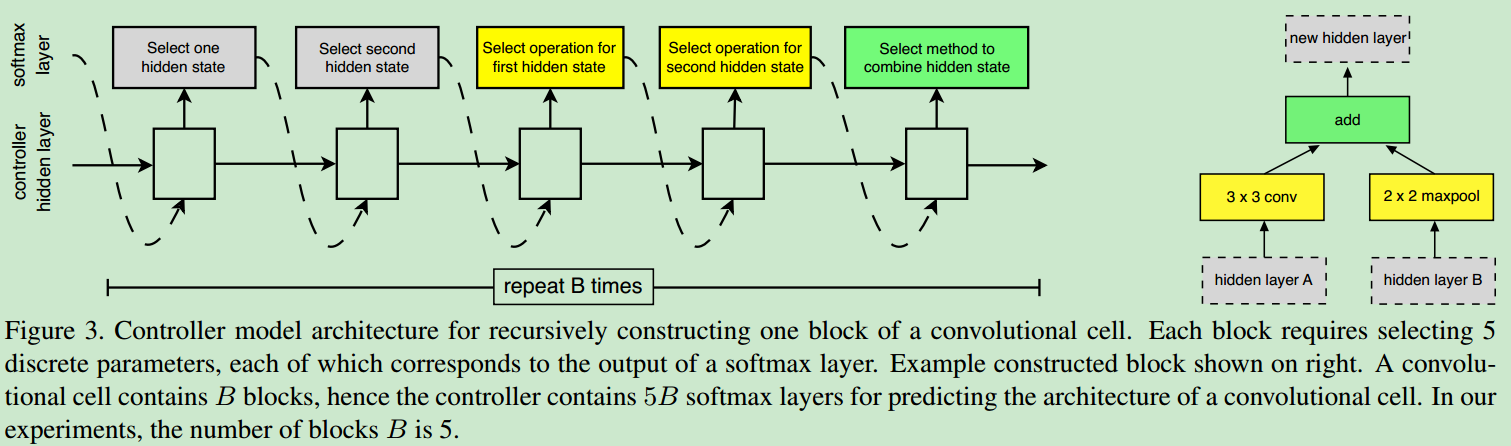
- 作者将基于RL的搜素与随机搜索进行对比,发现效果差别并不是很大,可以推断出、
- 这种NasNet得到的结构本身就是很好的
- 随机搜索这个baseline本身就很高。
results
on cifar 10
- 论文中每个cell包含5个block,搜索之后得到的最好的结构如下
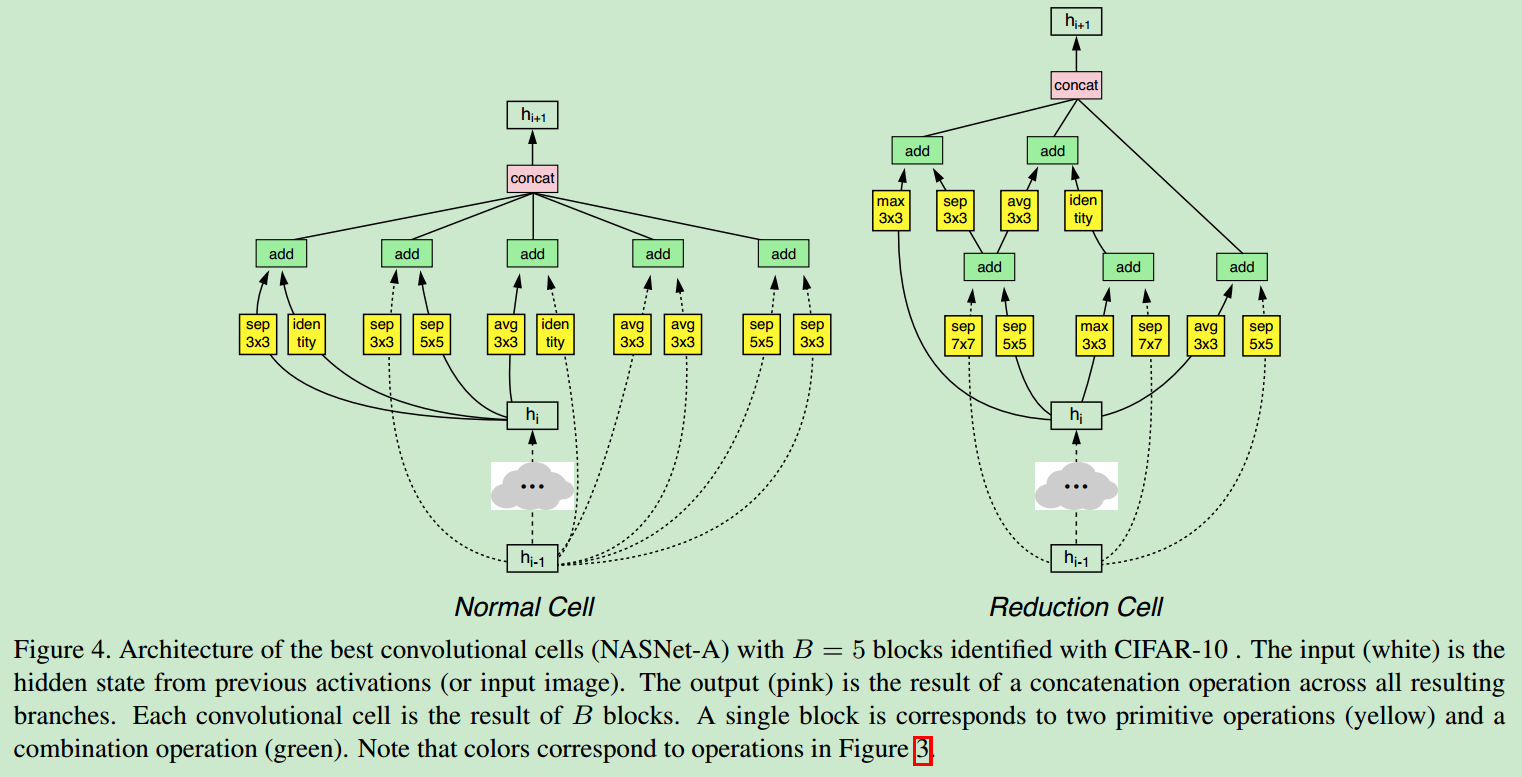
在cifar10上的表现如下
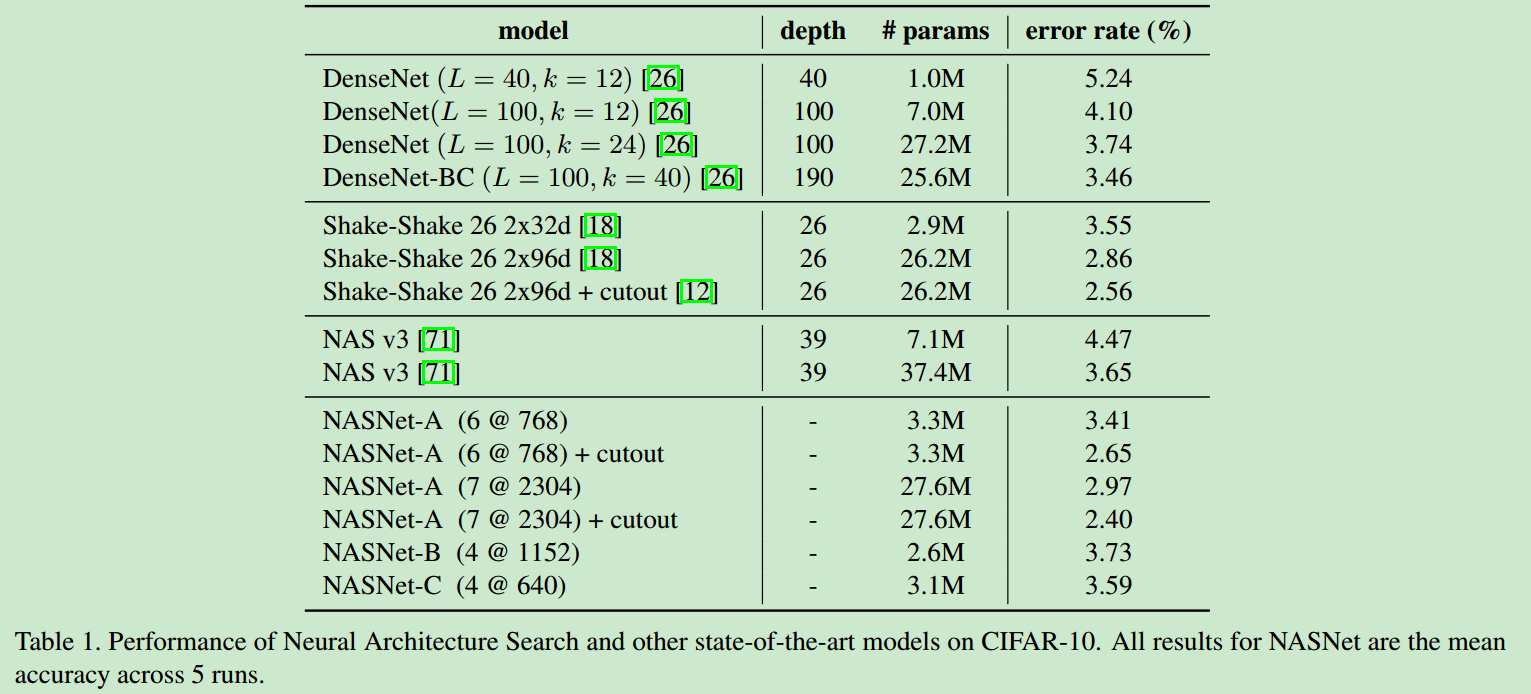
on coco
- 在coco数据集上展开了detection的实验,验证Naset生成的模型的泛化能力,将其作为fasterRCNN的backbone,得到的结果秒杀其他人工设计的一众方法。
search method
- 将RL based search与random search进行对比,验证了RL based search的优越性。
conclusion
- 论文最主要的共享就是设计搜索空空间,将搜索空间与模型复杂度进行解耦,从而保证模型搜索与设计过程的快速性与泛化能力,同时方便模型结构的迁移。
MnasNet
abstract
- 在给移动设备设计网络结构时,需要在保证精度的前提下,提升其速度,在之前的NAS、NasNet等工作中都没有考虑到inference latency这一情况,本文中同时考虑到准确度和latecny两个目标,即在搜索的过程中的目标函数是多目标的。
- 之前的latency都是使用一些间接的指标,如flops等,本文直接时间inference time作为推断延迟的时间,这比之前的间接指标要更加准确一些。、
- 在分类任务和检测任务上面都超过了mobilenet系列的效果。
contribution
- 介绍了一种基于RL的多目标优化搜索方法,用于找到同时满足高准确度和低延迟的模型结构。
- 提出了一种新型的分层搜索空间,用于平衡灵活性与搜索空间的尺寸。
- 搜索得到的模型性能超过了mobilenet。
problem formulation
- 主要的公式如下
$$\mathop maximize_{(m)} {\kern 10pt} ACC(m) \times {[\frac{LAT(m)}{T}]^w}$$
其中
$$w = \left{ \begin{array}{l}
\alpha ,{\kern 5pt} if{\kern 5pt} LAT(m) \le T\
\beta ,{\kern 5pt} otherwise
\end{array} \right.$$
从而可以将多目标函数变为单目标函数,设计不同的$\alpha$与$\beta$就可以设计有不同侧重点的模型结构。
Mobile Neural Architecture Search
Search Algorithm
- 基于梯度下降的RL算法用于搜索最优模型结构。
Factorized Hierarchical Search Space
- 结构示意图如下

每个block中含有若干个网络层,同一个blcok中的网络层的结构相同,搜索空间就是所有这些网络层的结构。
- 假设模型被分为B个blocks,每个子空间有S个解,每个block有N个layer,则论文中这种分层搜索结构的搜索空间大小为$S ^ B$,而平铺结构的搜索空间大小为$S ^ {N \cdot B}$,这种分层结构比平铺结构的搜索空间大小要小得多。
results
- 分类性能表现如下

检测性能如下
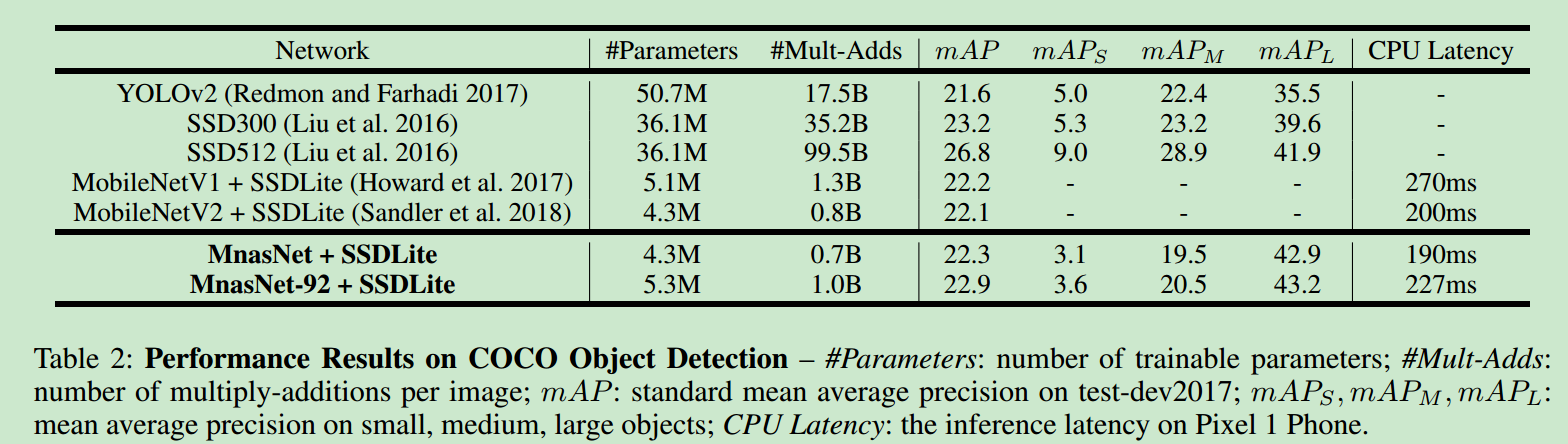
architecture discussion
- 引入网络latency指标时,搜索方法可以自动搜索计算量较小的方法。
- 对于网络结构差异较大的模型,它在精度和实效性的平衡性方面做得更好。
conclusion
- 提出了MNasNet,将模型精度与时效性作为目标,可以使得生成的模型在移动设备上使用,综合性能超过了mobilenet。
- 使用分层搜索结构,可以在精度与时效性方面有更好的平衡。