前言
- 这其实算是挺早的一篇文章了,但是之前在面试roadstar时,面试官说了他关于语义分割这一块的实验经验,说
较大的batchsize和多尺度的池化(金字塔池化)、以及困难样本的挖掘都可以提升语义分割的精度,本文是多尺度池化相关,因此在这里回顾一下。
abstract
- 论文地址:https://arxiv.org/pdf/1612.01105.pdf
- 论文提出了PSPNet,通过金字塔池化模型去获取
global context information。 - PSPNet在ImageNet2016、Pascal VOC、cityscapes等数据集上都超过了SOTA。
introduction
- 场景理解的主要难点在于场景中像素类别之间的差异很小。
- 之前语义分割或者场景理解时,主要的网络结构是FCN,但是作者发现FCN有个很明显的问题:它没有办法获取global context information。之前也有学者基于这个问题提出了
spatial pyramid network。 - 与之前的网络结构不同,作者提出了
PSPNet,除了使用dilated convolution用于FCN之外,也结合global pyramid pooling,全局和局部的信息相结合,可以进一步提升预测结果的性能。 - 论文主要的contribution如下
- 提出了PSPNet网络结构。
- 提出了deeply supervised loss的优化策略,可以用于ResNet中。
- 刷新了
scene parsing的SOTA,同时公布了很多细节。
Pyramid Scene Parsing Network
Important Observations
- 论文中提到
ADE20K dataset在分割任务中主要有以下一些问题:- 不匹配的上下文关系,即比如说水上一般是可以有船,但是不能有车的。
- 容易混淆的类别,比如说有field和earth这两个类别是比较容易混淆的。
- 不显眼的类别,即特定类别所占的像素太少,比如建筑物上的钟摆,这在池化的时候相对于那些大的物体,更加容易被忽视。
Pyramid Pooling Module
- 在DNN中,虽然有些层感受野的大小在理论上大于输入图像,但是在实际的使用过程中,high level layers的感受野基本都是远小于理论值的。因此许多网络也无法充分利用
global context information,论文中使用global prior representation来解决这个问题。 - 之前有使用
global average pooling来作为global prior representation,同时可以使得不同输入大小的图像都可以经过卷积之后变成固定维度,用于后续的分类,但是这会丢失大量的信息(最后的feature map size为1)。 - 为了减少
context information loss,论文中提出了hierarchical global prior,可以包含不同sub-regions中不同尺度的信息,模型主要框图如下
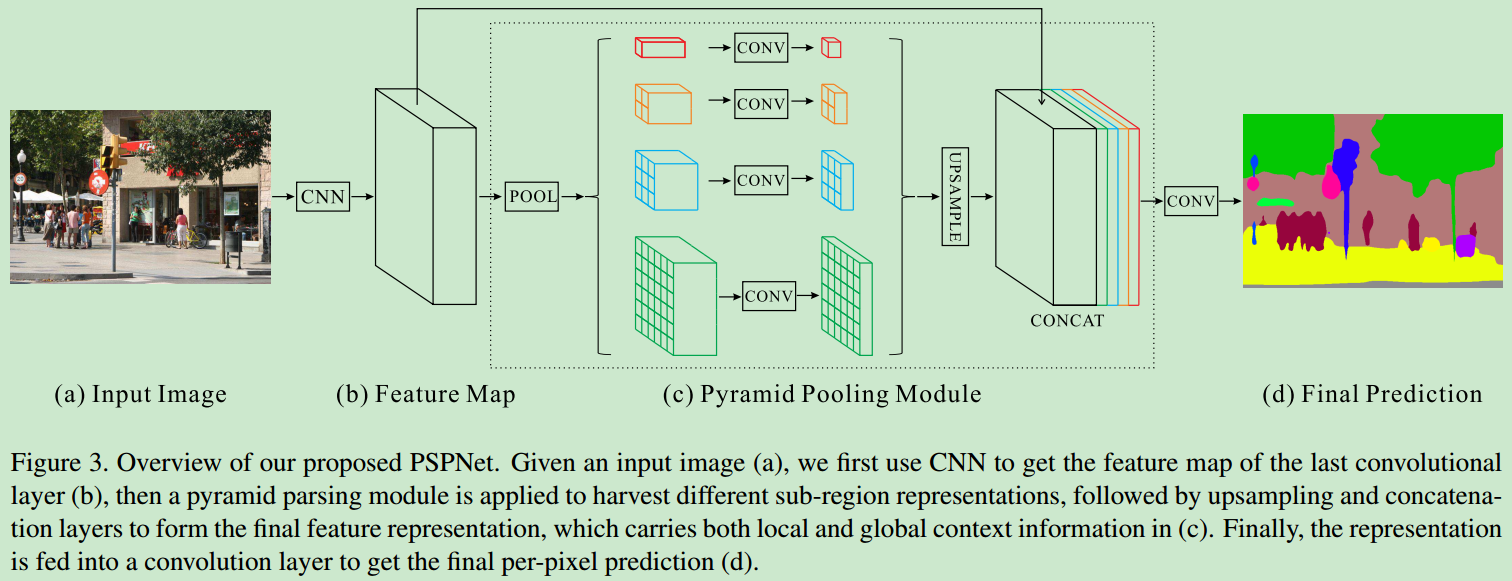
经过多尺度的池化之后,使用1X1 conv对其进行降维,之后使用双线性插值进行上采样,并做concatenate,最后conv得到最终地feature map。
Network Architecture
- 网络的backbone是ResNet101,除了最后的loss function之外,还在
res4b22后面加了一个auxiliary loss。
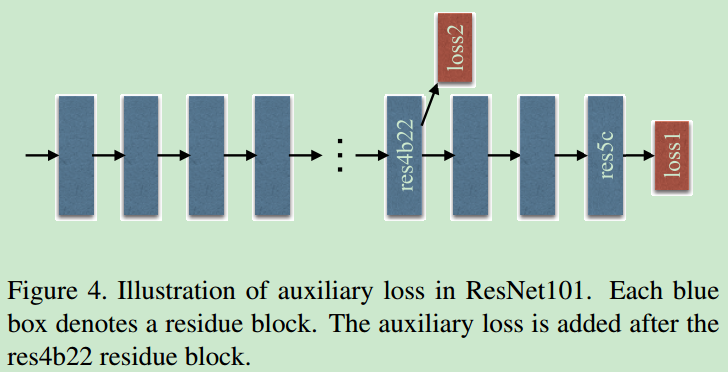
Deep Supervision for ResNet-Based FCN
- 传统的resnet只有一个loss,论文中,加上一个auxiliary loss,这个auxiliary loss在BP的时候在所有之前的网络层中都起了作用,而非传统的只对
low-level layers起作用。此外,对loss与auxiliary loss进行加权,最后的softmax loss起主导作用,而auxiliary loss用于改善训练过程。 - 在这里需要注意的是,因为
aux layer与最后的output layer的feature map size是相同的,因此aux layer在训练过程中的gt label与output layer的gt label是相同的,它们经过softmax之后进行BP。具体可以参见gluoncv中PSPNet的具体实现方式:https://github.com/dmlc/gluon-cv/blob/master/gluoncv/model_zoo/pspnet.py
experiment
- 作者主要是针对以下几个方面来进行比较
- baseline
- 是否采用多个池化
- max pooling还是average pooling
- 是否使用auxiliary loss以及auxiliary loss的weight
- 在
Pascal VOC上的对比实验结果如下
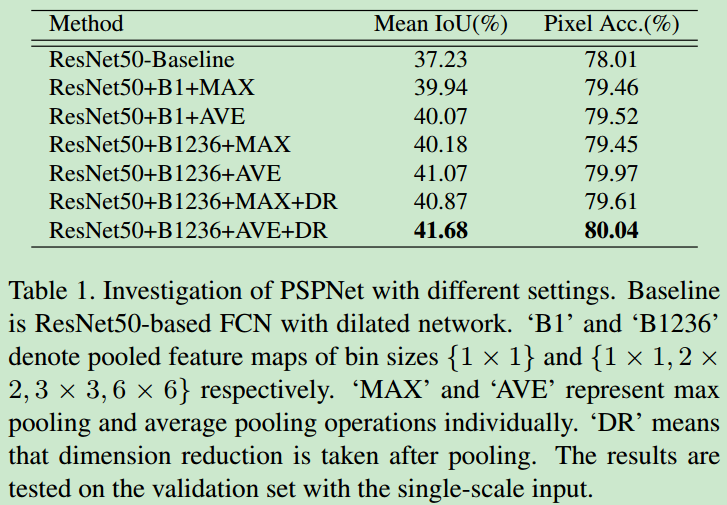
- 作者也在ImageNet、cityscapes上做了实验,具体实验结果可以见论文,最后的结论就是PSPNet得到的分割结果很好,加上data augmentation、auxiliary loss、multi scale之后,性能都会有所提升。
conclusion
- 论文最主要的就是提出了PSPNet用于scene parsing,此外也提出了
deeply supervised optimization strategy,用于优化resnet作为backbone的FCN网络结构,同时公布了代码。