abstract
- 在
DCN v1中提出了可变形的卷积网络,本文中讲这种可变形卷积应用到更多地layer中去,进一步提升了模型性能。 - 此外,作者不仅使得filter的shape可以学习,还提出了filter的amplitude可以学习的方法。
- 为了使得网络可以更好地学习,提出了
feature mimicking scheme,类似于distillation,使得网络可以具有更好地object focus以及classification power。 - 在coco上取得了最好的结果。
introduction
- 主要就是介绍了之前detection框架中的一些局限性。
- 论文中提出了
DCN v2,使得网络可以同时学习样本的空间分布与特征幅值(spatial distribution and the relative influence)。 - 为了提升该方法的
modeling capacity,作者借鉴模型蒸馏的方法去训练网络,使用RCNN作为teacher network。RCNN在训练的过程中是对图像进行了crop,之后再用于分类任务,因此不会受到其他非roi区域的影响;作者希望DCN v2也具有这种不被非roi区域影响的性质,因此在训练的过程中,引入了feature mimicking loss,希望学习到的特征能够与RCNN尽量相似(因为RCNN学到的特征都是roi区域的)。
Analysis of Deformable ConvNet Behavior
Spatial Support Visualization
- 为了对论文方法有更好的理解,作者对一些过程进行了可视化(我觉得这个非常值得借鉴,即去探讨特定的结构对网络究竟有什么样的影响或者说是怎么影响的)。
Effective receptive fields
- 不是所有在感受野内的像素都对最后的结果又同等的贡献,这些区别可以使
Effective receptive fields进行表征,计算方法为:node response对每个像素处强度扰动的梯度。
Effective sampling / bin locations
- 其实这个在v1中就已经可视化过了,计算方法为:
node response相对于采样位置的梯度,主要是看bin对网络的contribution。
Error-bounded saliency regions
之前在有关图像显著性相关的工作中提到,对于特定的network node,如果去除图片中与该node无关的部分,则不会影响node response。因此一个node的
support region其实在full image中有个最小的范围,这个范围内的区域经过node得到的response与full image的node response是相同的,而且这个范围无法再继续缩小。之前常规卷积、DCN v1以及DCN v2对于上述三种情况的可视化效果如下。
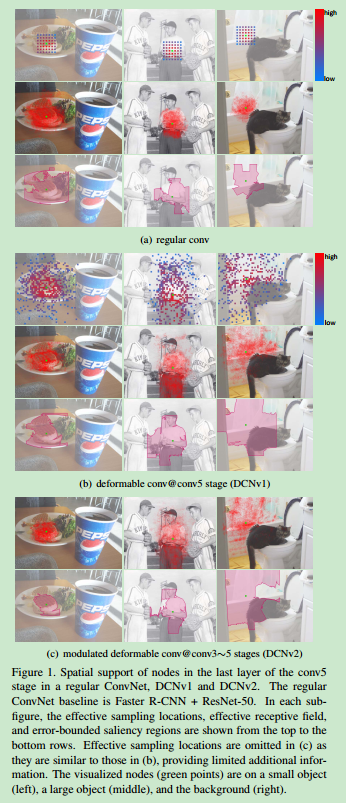
可以看出DCN v2对于空间分布的提取更加有效(从点与边缘的精细程度可以看出来)。
More Deformable ConvNets
Stacking More Deformable Conv Layers
- 之前在v1中,只对resnet的conv5使用了deformable conv,本文中,对conv3~5都使用了deformable conv,这也是性能提升贡献最大的地方。
Modulated Deformable Modules
- 在v1中,只对offset进行学习,v2中对amplitude也进行学习(当offset为0,amplitude为1,时,退化成常规的conv op),计算方法如下。
$$y({p_0}) = \sum\limits_{p_n \in \Re } {w(p_n) \cdot x(p_0 + p_n + \Delta p_n) \cdot \Delta m_n}$$
在pooling时,也引入$\Delta m_n$的超参数。
R-CNN Feature Mimicking
- 在detection训练过程中,如果有大量不在roi内的内容,可能会影响提取的特征,进而降低最终得到的模型的精度。RCNN训练时是裁剪出roi,使用roi进行训练,因此大大减小了无关区域对特征提取的影响。但是如果直接将RCNN引入到fasterRCNN中,会导致训练和测试的时间大大增加。
- 作者做了实验,结果说明,即使使用了
modulated deformable modules,也无法使得fasterRCNN训练的很好(模型学到的东西在特征提取方面的表现较差)。 - 引入
feature mimic loss,希望网络学到的特征与裁剪后的图像经过RCNN得到的特征是相似的,在这里设置loss如下,采用的是cos相似度评价指标。
$$L_{mimic} = \sum\limits_{b \in \Omega } {[1 - \cos (f_{RCNN}(b) - f_{FRCNN}(b))]} $$
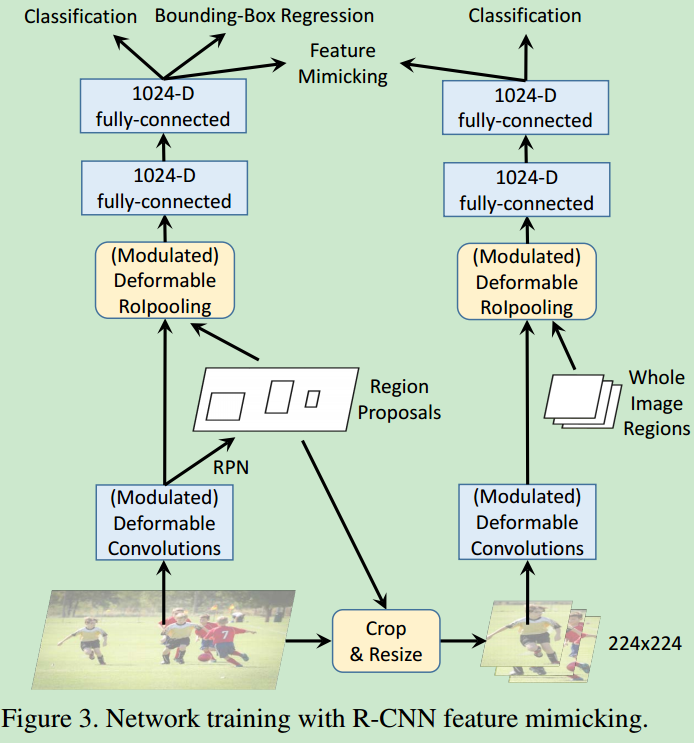
- 因为背景一般都比较复杂(边界、面积、颜色分布等),因此对于背景区域,考虑了更多的context information,避免生成
false positive的detection结果。 - feature mimicking的网络结构如下
experiments
Enriched Deformation Modeling
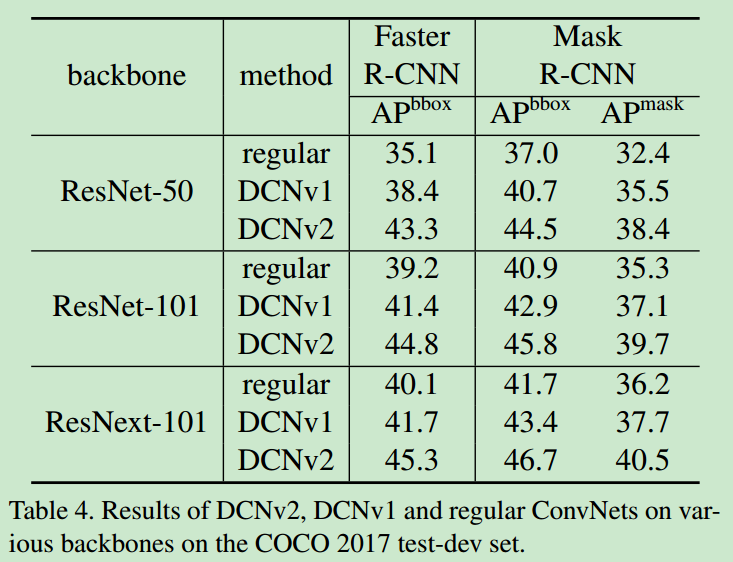
- 在coco上的结果如下
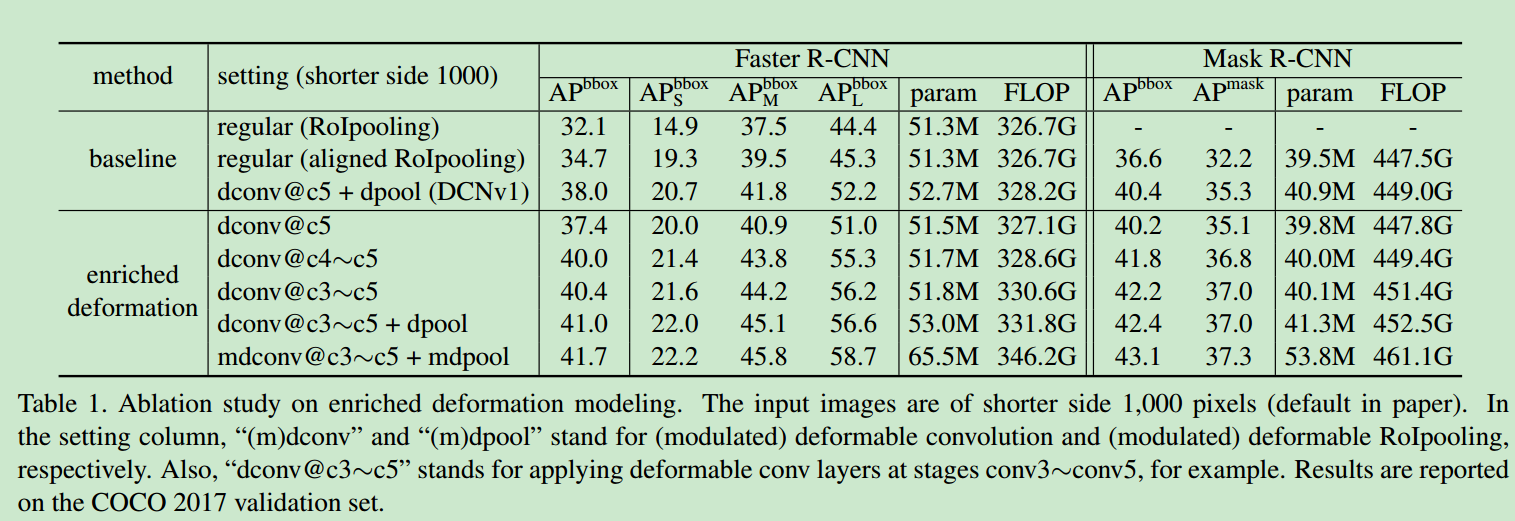
- 感觉主要还是更多的deformable conv大大提升了任务的AP,论文中的
Modulated Deformable Modules其实只带来了不到1个点的性能提升。
R-CNN Feature Mimicking
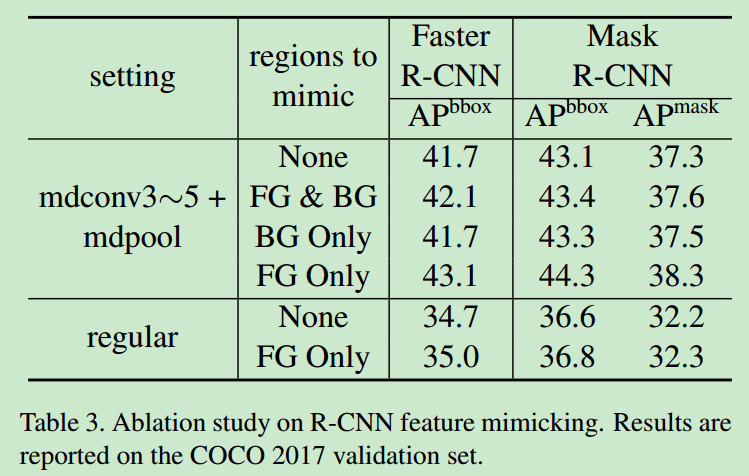
- feature mimicing对模型性能的影响如下图,可以看出还是会带来一些提升的,虽然并不是很明显。
stronger backbones
- 在不同backbone上的对比效果如下,v2在所有backbone上的优势都是很明显的。
conclusion
- 提出了v2,主要还是希望网络关注有关的图像区域的能力更强,一方面是从filter变形的角度进行改进,另一方面是使用distillation的方法,使得网络能够学习更多与roi相关的信息,这在detection与instance segmentation任务上都刷新了STOA。
其他链接
- 知乎上也有很精彩的讨论:https://www.zhihu.com/question/303900394